Firecrawl 快速部署指引
Firecrawl 是一个易于使用的网站内容爬取工具,也就是常规意义上的爬虫。不同的是 Firecrawl 在数据清洗环节为 AI 应用做了优化,能够将网站较好的转换为 Markdown 格式,同时又不至于让 Firecrawl 的使用过于复杂。
当然这里介绍 Firecrawl 的一大重要原因是 Firecrawl 是 Dify 默认支持的数据抓取工具,能够与 Dify 进行较好的集成。
在开始之前
本文所使用的安装环境为:Docker version 27.5.1 / Docker Compose version v2.32.4。
Firecrawl 除了在本地部署以外,还可以直接使用其云服务,直接访问官网注册账号即可使用。相比与云服务,社区版会缺少相当一部分功能,大致功能划分可以参照下图官方图解:
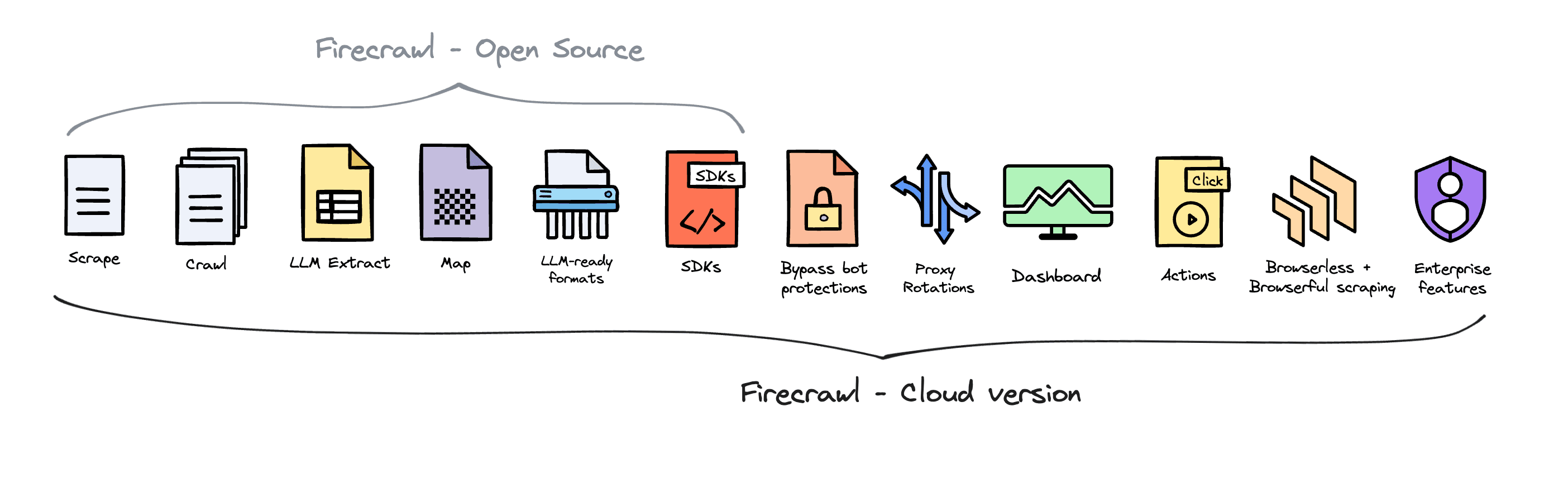
与 Dify 不同,Firecrawl 的社区版和云服务版基本是两个东西。如果只是与 Dify 结合使用,也就是本文指引将会介绍的内容来说,社区版是完全足够使用的。
部署 Firecrawl
Firecrawl 官方并未提供打包好的容器,需要通过官方仓库打包镜像再运行。你可以在 Firecrawl Releases 页面找到最新的 Firecrawl 版本号,这在之后的构建容器时会使用到。
官方介绍的方式是从源代码自行构建镜像,但是由于国内网络环境原因,构建镜像大概率会失败。个人更推荐使用如 Github Actions 的服务来帮你构建镜像。本文会按顺序介绍这两种方式,如果你的网络存在问题,可直接跳跃至 从 Github Actions 构建镜像。
从源代码构建
按照下列步骤构建镜像
git clone https://github.com/mendableai/firecrawl.git
cd firecrawl
git reset main --hard
git pull --force
git checkout v1.6.0 # 替换成你在 Firecrawl Releases 中找到的最新版本如果你的设备存在网络限制,你可以使用
git clone -c http.proxy=http://127.0.0.1:7890 -c https.proxy=https://127.0.0.1:7890 https://github.com/mendableai/firecrawl.git来克隆仓库(注意替换代理地址为自己的地址)
在 firecrawl 目录中,新建 .env 文件,内容参照下文进行修改:
# ===== 必须环境变量 ======
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
## Docker 部署的情况下不需要更改这些链接
REDIS_URL=redis://redis:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
## 开启 DB authentication,开启此项需要完成 supabase 配置
USE_DB_AUTHENTICATION=true
# ===== 可选环境变量 ======
# SearchApi key. Head to https://searchapi.com/ to get your API key
SEARCHAPI_API_KEY=
# SearchApi engine, defaults to google. Available options: google, bing, baidu, google_news, etc. Head to https://searchapi.com/ to explore more engines
SEARCHAPI_ENGINE=
# Supabase 配置(用于支持 DB authentication、高级日志记录等。)
SUPABASE_ANON_TOKEN=
SUPABASE_URL=
SUPABASE_SERVICE_TOKEN=
# 其他可选配置
# 如果您已经设置了认证,并想要使用真实的API密钥进行测试,请设置此值
TEST_API_KEY=
# 如果您想要测试单页爬取速率限制,请设置此值
RATE_LIMIT_TEST_API_KEY_SCRAPE=
# 如果您想要测试站点爬取速率限制,请设置此值
RATE_LIMIT_TEST_API_KEY_CRAWL=
# 如果您想要使用 Scraping Be 来处理 JS 阻塞,请设置此值
SCRAPING_BEE_API_KEY=
# 为依赖于 LLM 的功能添加(如图片 Alt 文本生成等)
OPENAI_API_KEY=
# 队列管理面板访问密钥,若 Firecrawl 为公开部署,则需要设置此值
BULL_AUTH_KEY=@
# 如果要使用 llamaparse 来解析 PDF 文件,请设置此值
LLAMAPARSE_API_KEY=
# 如果要将健康状态信息发送至 slack,请设置此值
SLACK_WEBHOOK_URL=
# 如果您想要发送如作业日志之类的 posthog 事件,请设置此值
POSTHOG_API_KEY=
POSTHOG_HOST=
# 文档并未对此部分做出解释
STRIPE_PRICE_ID_STANDARD=
STRIPE_PRICE_ID_SCALE=
STRIPE_PRICE_ID_STARTER=
STRIPE_PRICE_ID_HOBBY=
STRIPE_PRICE_ID_HOBBY_YEARLY=
STRIPE_PRICE_ID_STANDARD_NEW=
STRIPE_PRICE_ID_STANDARD_NEW_YEARLY=
STRIPE_PRICE_ID_GROWTH=
STRIPE_PRICE_ID_GROWTH_YEARLY=
# Fire Engine 的封测版配置,保留为空
FIRE_ENGINE_BETA_URL=
# Playwright 服务的代理设置(另外,你还可以使用像 oxylabs 这样的代理服务,这样就可以每次请求时自动更换IP)
PROXY_SERVER=
PROXY_USERNAME=
PROXY_PASSWORD=
# 设置此项阻止媒体链接来节省代理流量/带宽
BLOCK_MEDIA=
# 本地部署 FireCrawl 时,设置此项为 webhook 的 URL
SELF_HOSTED_WEBHOOK_URL=
# 用于邮件服务的 Resend API Key
RESEND_API_KEY=
# LOGGING_LEVEL,输出日志等级,可选项如下
# NONE - No logs will be output.
# ERROR - For logging error messages that indicate a failure in a specific operation.
# WARN - For logging potentially harmful situations that are not necessarily errors.
# INFO - For logging informational messages that highlight the progress of the application.
# DEBUG - For logging detailed information on the flow through the system, primarily used for debugging.
# TRACE - For logging more detailed information than the DEBUG level.
# Set LOGGING_LEVEL to one of the above options to control logging output.
LOGGING_LEVEL=INFO如果你觉得头大,那么按照本文的教程指引,你只需要将 .env 文件设置为如下内容:
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://redis:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
USE_DB_AUTHENTICATION=false
BULL_AUTH_KEY=@保存 .env 文件,之后执行以下命令来构建和运行 Firecrawl:
sudo docker compose build
sudo docker compose up从源代码构建时,镜像给构建完成之后可以直接启动,访问 http://<Firecrawl-IP>:3002/admin/@/queues 即可打开数据抓取队列管理页面,此处 URL 中的 @ 为 .env 文件中的 BULL_AUTH_KEY 设置值。
从 GitHub Actions 构建
Github Actions 简单理解就是可以利用 Github 的公共服务器资源做一些事情,由于服务器是 Github 的,就没有什么网络问题。
此处对此不多介绍,可以直接使用封装好的仓库:MitsuhaYuki/firecrawl-docker-image
如果你对 Github Actions Workflow 感兴趣,此处使用的脚本源代码可以点击这里查看。
首先打开 Releases 页面,下载最新版中附件中的 docker-images.zip 文件,在本地进行解压得到 api-image.tar 和 playwright-image.tar,将这两个文件上传到服务器,运行以下指令导入镜像到 Docker:
sudo docker load -i api-image.tar
sudo docker tag api:v1.6.0 firecrawl/api:v1.6.0
sudo docker load -i playwright-image.tar
sudo docker tag playwright:v1.6.0 firecrawl/playwright:v1.6.0之后就可以按照通常流程,首先创建容器编排 docker-compose.yaml
x-common-env: &common-env
REDIS_URL: ${REDIS_URL:-redis://redis:6379}
REDIS_RATE_LIMIT_URL: ${REDIS_URL:-redis://redis:6379}
PLAYWRIGHT_MICROSERVICE_URL: ${PLAYWRIGHT_MICROSERVICE_URL:-http://playwright-service:3000/scrape}
USE_DB_AUTHENTICATION: ${USE_DB_AUTHENTICATION}
OPENAI_API_KEY: ${OPENAI_API_KEY}
OPENAI_BASE_URL: ${OPENAI_BASE_URL}
MODEL_NAME: ${MODEL_NAME}
MODEL_EMBEDDING_NAME: ${MODEL_EMBEDDING_NAME}
OLLAMA_BASE_URL: ${OLLAMA_BASE_URL}
SLACK_WEBHOOK_URL: ${SLACK_WEBHOOK_URL}
BULL_AUTH_KEY: ${BULL_AUTH_KEY}
TEST_API_KEY: ${TEST_API_KEY}
POSTHOG_API_KEY: ${POSTHOG_API_KEY}
POSTHOG_HOST: ${POSTHOG_HOST}
SUPABASE_ANON_TOKEN: ${SUPABASE_ANON_TOKEN}
SUPABASE_URL: ${SUPABASE_URL}
SUPABASE_SERVICE_TOKEN: ${SUPABASE_SERVICE_TOKEN}
SCRAPING_BEE_API_KEY: ${SCRAPING_BEE_API_KEY}
SELF_HOSTED_WEBHOOK_URL: ${SELF_HOSTED_WEBHOOK_URL}
SERPER_API_KEY: ${SERPER_API_KEY}
SEARCHAPI_API_KEY: ${SEARCHAPI_API_KEY}
LOGGING_LEVEL: ${LOGGING_LEVEL}
PROXY_SERVER: ${PROXY_SERVER}
PROXY_USERNAME: ${PROXY_USERNAME}
PROXY_PASSWORD: ${PROXY_PASSWORD}
SEARXNG_ENDPOINT: ${SEARXNG_ENDPOINT}
SEARXNG_ENGINES: ${SEARXNG_ENGINES}
SEARXNG_CATEGORIES: ${SEARXNG_CATEGORIES}
services:
playwright-service:
environment:
PORT: 3000
PROXY_SERVER: ${PROXY_SERVER}
PROXY_USERNAME: ${PROXY_USERNAME}
PROXY_PASSWORD: ${PROXY_PASSWORD}
BLOCK_MEDIA: ${BLOCK_MEDIA}
image: firecrawl/playwright:v1.6.0
networks:
- backend
api:
command: ["pnpm", "run", "start:production"]
depends_on:
- redis
- playwright-service
environment:
<<: *common-env
HOST: "0.0.0.0"
PORT: ${INTERNAL_PORT:-3002}
FLY_PROCESS_GROUP: app
image: firecrawl/api:v1.6.0
networks:
- backend
- default
ports:
- "${PORT:-3002}:${INTERNAL_PORT:-3002}"
worker:
command: ["pnpm", "run", "workers"]
depends_on:
- redis
- playwright-service
- api
environment:
<<: *common-env
FLY_PROCESS_GROUP: worker
image: firecrawl/api:v1.6.0
networks:
- backend
redis:
command: redis-server --bind 0.0.0.0
image: redis:alpine
networks:
- backend
networks:
backend:
driver: bridge
在容器编排同目录下,创建环境变量配置文件 .env,.env 文件详细配置参照上文 从源代码构建 有详细说明。
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://redis:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
USE_DB_AUTHENTICATION=false
BULL_AUTH_KEY=@使用命令 sudo docker compose -p firecrawl up -d 即可启动 firecrawl 服务,访问 http://<Firecrawl-IP>:3002/admin/@/queues 即可打开数据抓取队列管理页面,此处 URL 中的 @ 为 .env 文件中的 BULL_AUTH_KEY 设置值。
Firecrawl WebUI
当你访问队列管理页面时,会打开如下页面:
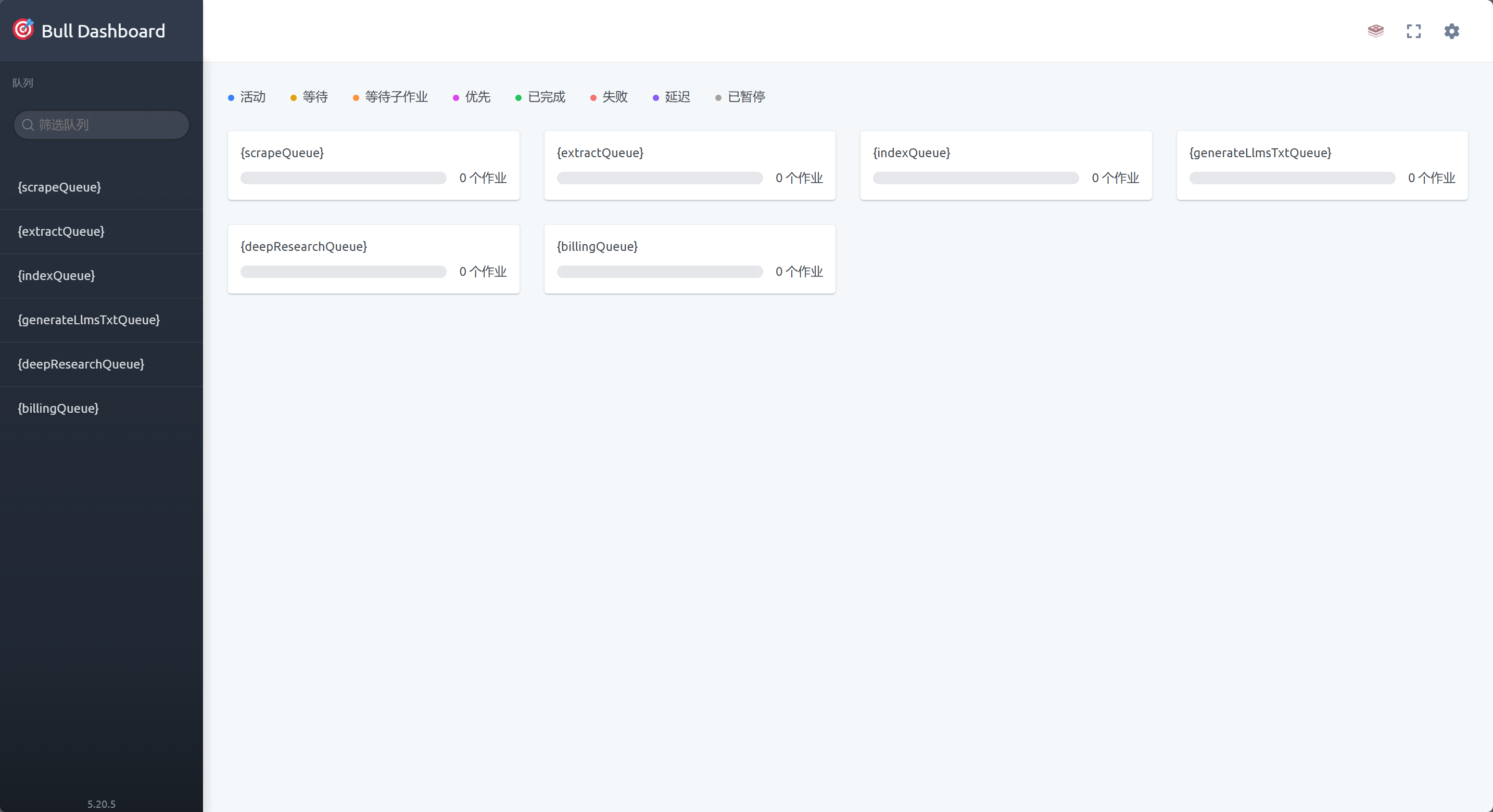
这是由于社区版目前无法调用 Fire Engine,所以没有后台管理页面。这个页面实际是内部数据抓取队列管理页面,对于基本操作管理也算是够用。
在 Dify 中集成 Firecrawl
配置 Firecrawl 集成
打开 Dify 工作室,点击右上角 头像-设置 来打开 Dify 设置:
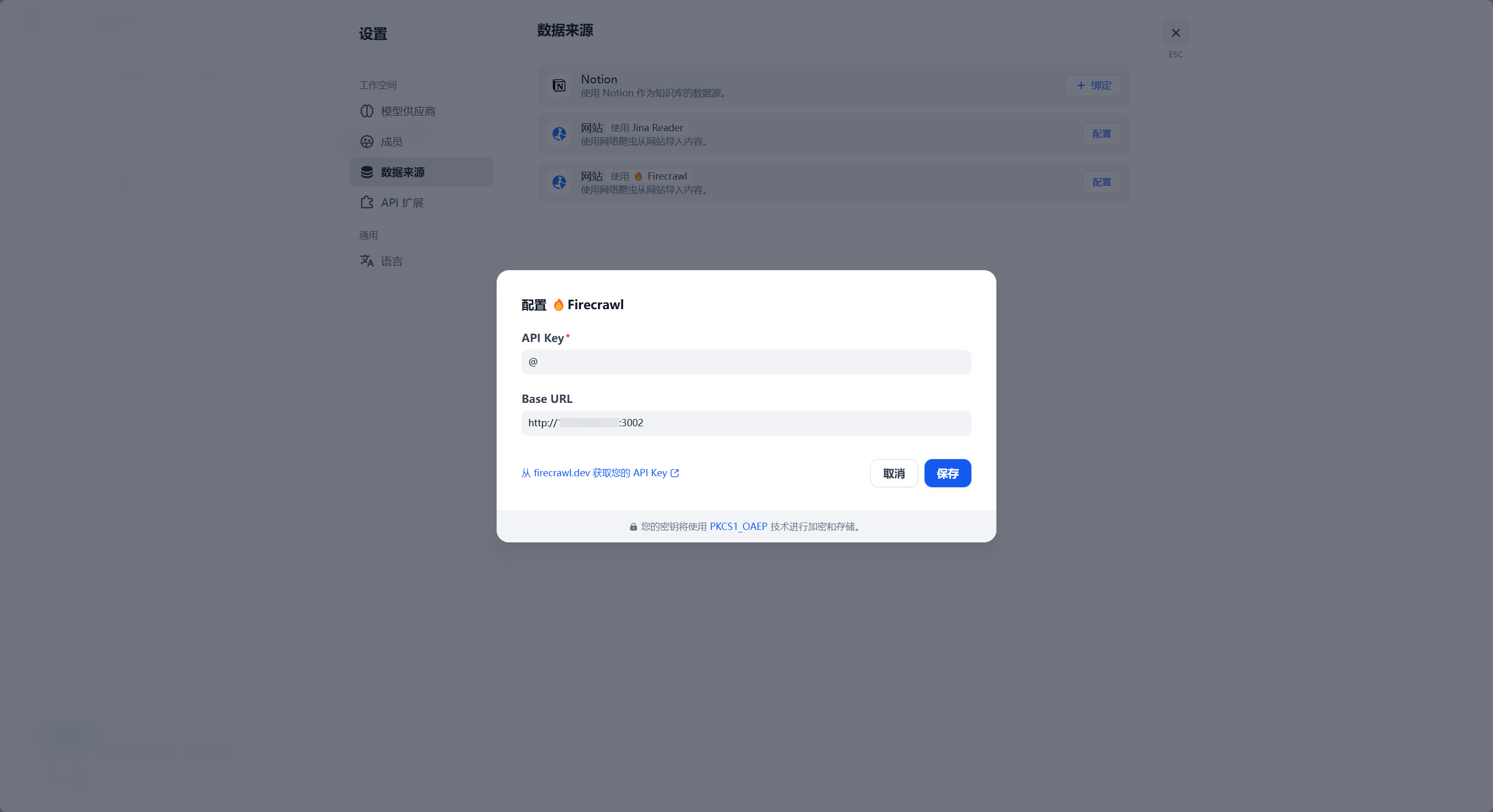
此处的设置项中,API Key 设置为先前 .env 文件配置中的 BULL_AUTH_KEY 的值,Base URL 为 http://<Firecrawl-IP>:3002。设置完成后点击保存,稍等片刻即可看到提示保存完成:
此时 Dify 的 Firecrawl 集成即配置完成。
在知识库中使用 Firecrawl
在 Dify 的知识库页面,选择 创建知识库 - 同步自 Web 站点 即可打开 Firecrawl 数据抓取配置。
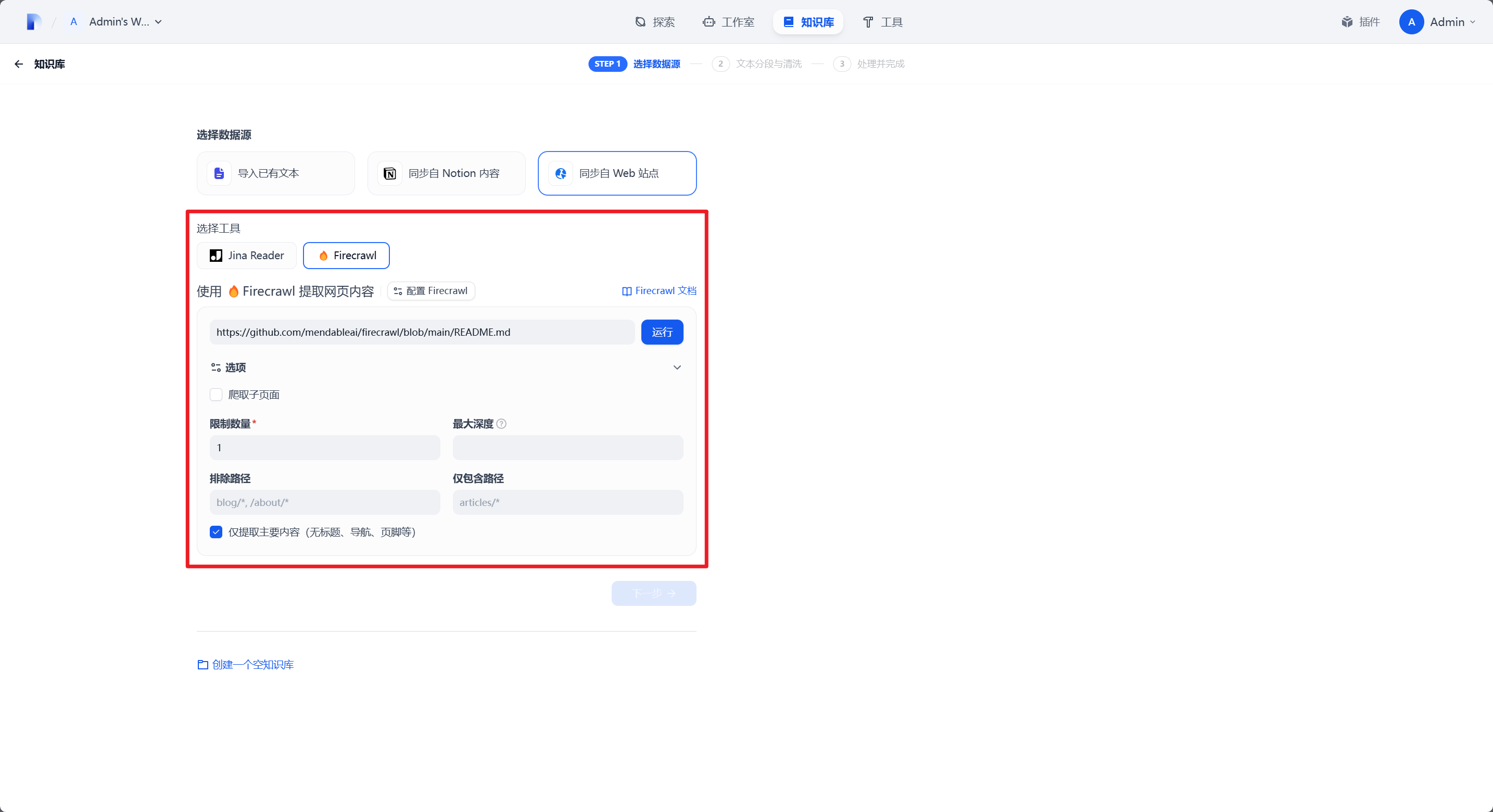
在这个页面中,最上方的输入框用于输入要抓取的 URL,下方是具体的数据爬取设置。
爬取子页面:如果给定链接所在的页面中存在子页面链接,是否要自动跟随并爬取子页面内容。
限制数量:最大允许爬取的页面数量,此处仅做测试设为 1,即只爬取给定页面。
最大深度:相对于给定链接的最大 URL 爬取深度,假设给定链接
http://testdomain.com/test/,如果此值设为 1 时,Firecrawl 只会爬取http://testdomain.com/test/*/的页面内容。排除路径:即黑名单,不允许抓取的 URL 路径。
仅包含路径:即白名单,只允许抓取给定的 URL 路径。
仅提取主要内容:顾名思义,抓取页面内容时排除无用块内容。
当配置完成后,点击 运行,开始爬取数据:
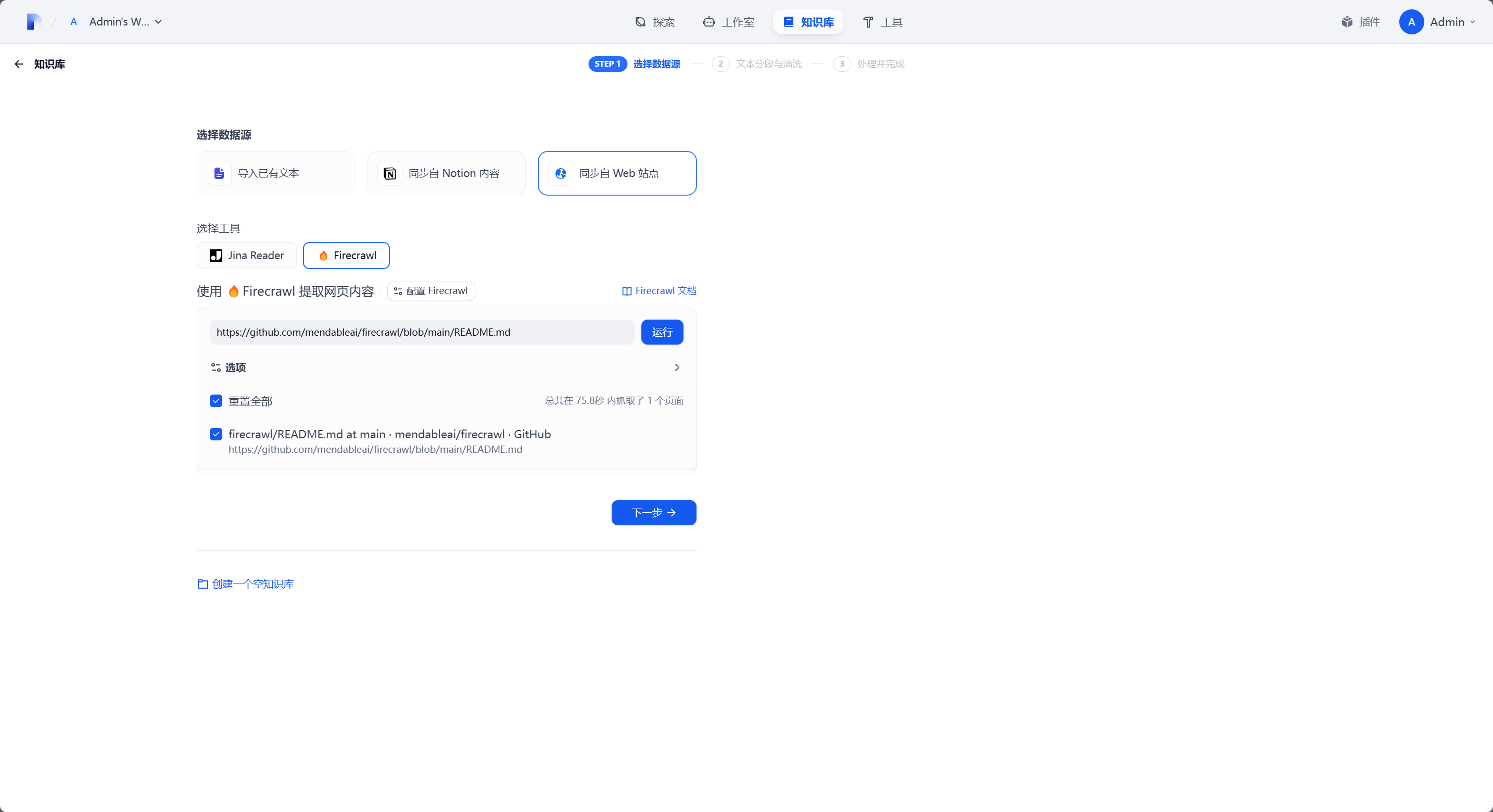
此处会显示除所有爬取到的页面,勾选你想要保留的页面,点击下一步进入知识库创建流程。
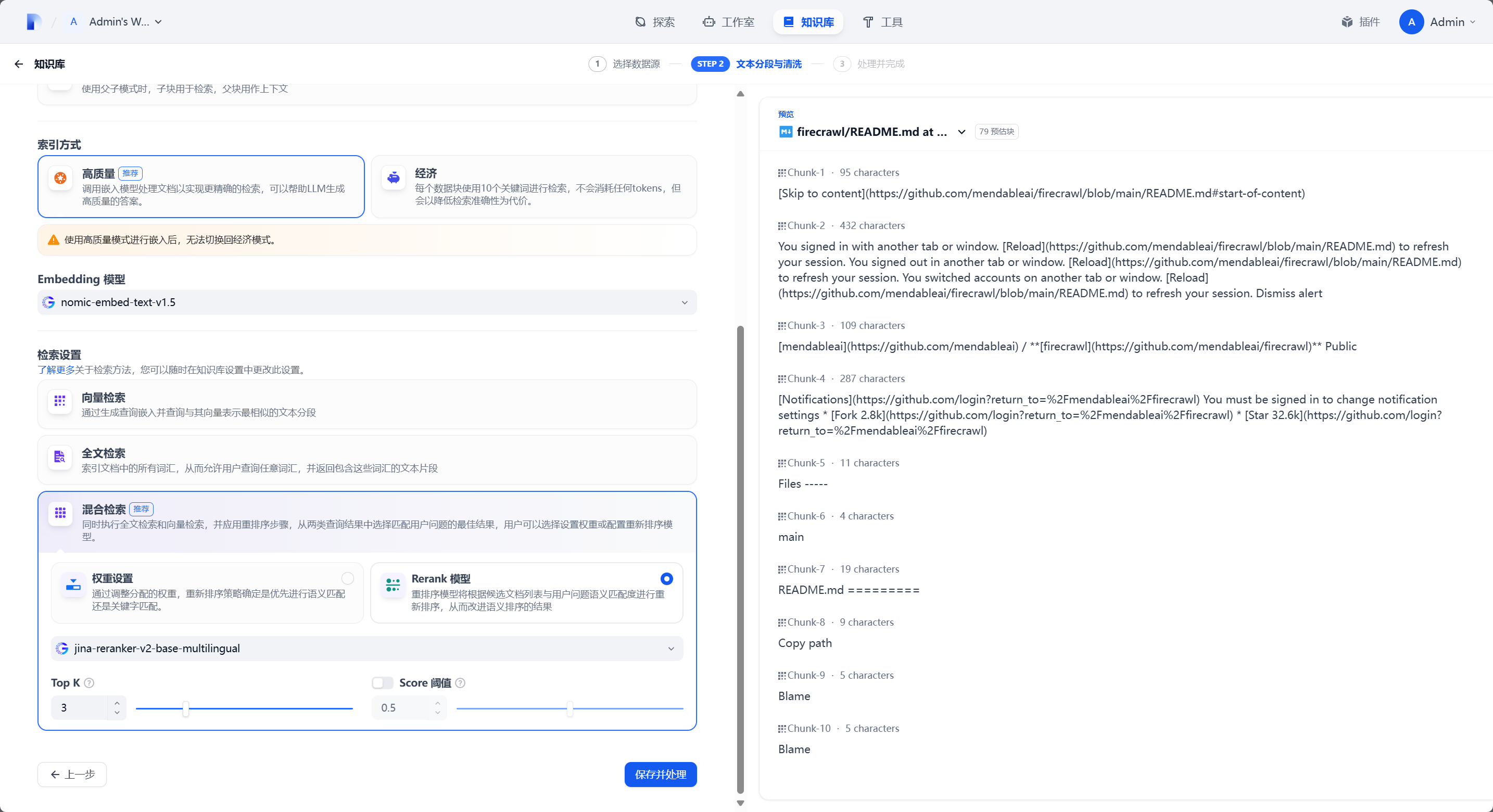
此处我是用的 nomic-embed-text 作为 Embedding 模型,jina-reranker-v2-base-multilingual 作为 Reranker 模型进行知识库创建。点击保存后稍等片刻等待知识库索引完成。
测试知识库调用
在聊天助手中知识库设置里添加刚刚创建的知识库,然后在 调试和预览 中点击右上角刷新就可以进行测试:
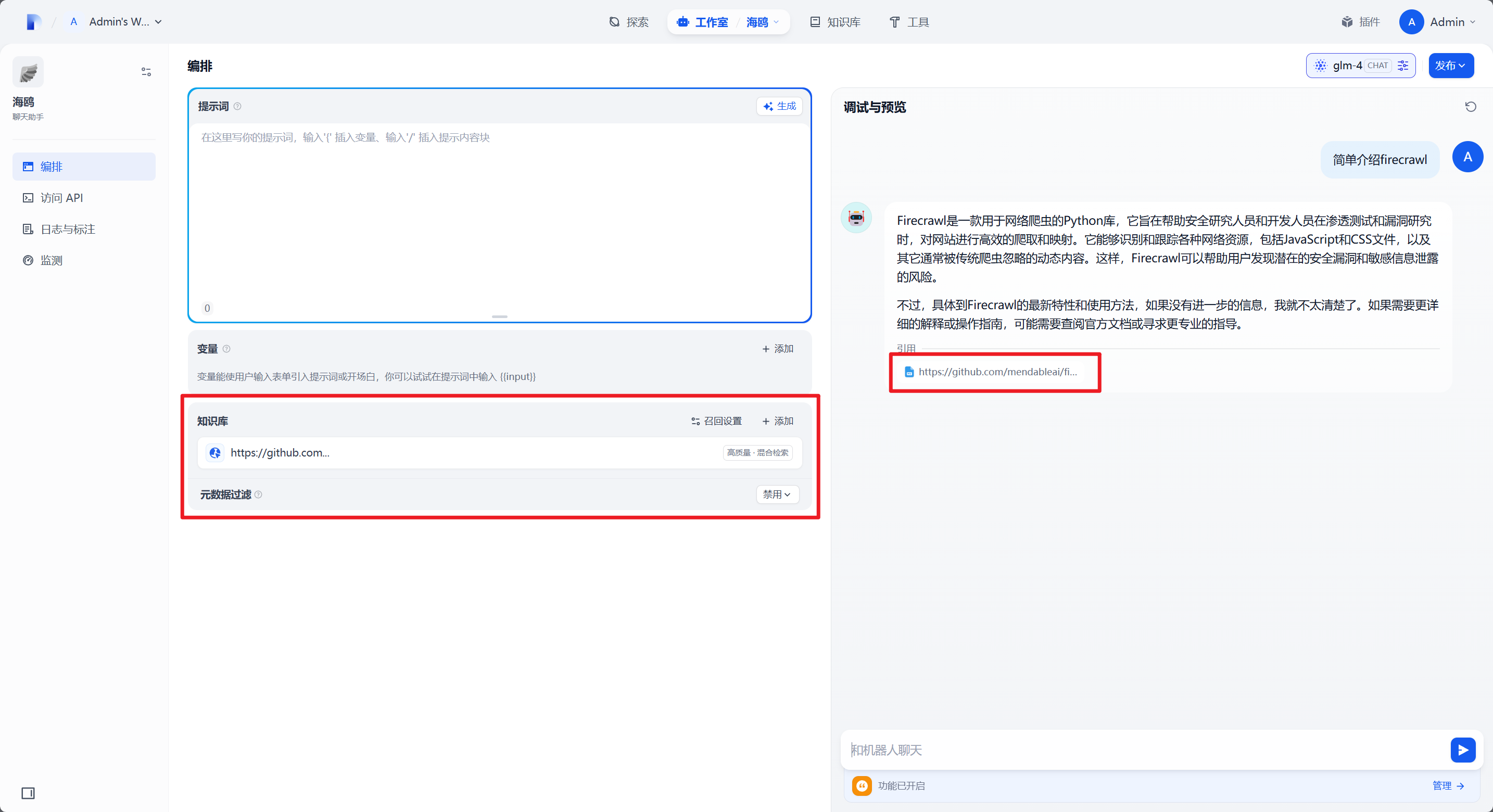
当调试区域显示正确的知识调用即代表知识库已可用。
拓展内容
Dify 调用错误,Firecrawl 后台报错 All scraping engines failed! Please double check...
检查你的 docker-compose.yaml 文件。在 api 服务的 netowork 设定中,除了 -backend 以外,还需要添加 -default 网络才能让容器正确连接网络。可以参照 从 GitHub Actions 构建 章节中的 docker-compose.yaml 中 service - api 块进行修改。
Dify 知识库创建时,爬取到快完成时卡住
截至写作时版本的 Dify(v1.1.3)在调用自部署版本的 Firecrawl 时,在抓取页面时有概率出现抓取到页面但不创建爬取任务的情况,此 Bug 在 Dify 使用云服务版本的 Firecrawl 时不存在。
其他 Firecrawl 调用问题
实际上在你使用自部署版 Firecrawl 时,受限制相比云服务版多很多,比如你只能爬取 https 站点、无法设置爬取速率限制、没有后台管理面板、没有自动 IP 池等等。如果你确实需要类似 Firecrawl 这样的工具,那么优先推荐使用云服务版本,会省心很多。
目前如果你要使用自部署 Firecrawl,那么只能推荐你提前区分好要爬取的站点,设置好只爬取自己需要的页面,或者干脆只用 Firecrawl 来爬取单一页面,那么基本就不会遇到问题。