LocalAI 部署完全指引
Ollama 很好用,但是它只能用来跑 LLM 和 Embedding,但其实还有一类比较重要的模型是 Reranker,以及多模态模型的视觉和音频支持,这些 Ollama 都没法运行。本文则介绍一个能够运行上述模型的工具:LocalAI。
在开始之前
对于 LocalAI 此处不做过多介绍,它是一个与 Ollama 类似的大模型运行基座。相比于 Ollama,LocalAI 支持的模型种类更多,除 LLM 以外,还支持多模态、Reranker、图像生成。同时 LocalAI 提供一个不能算是强大但还算是能用的 WebUI 来方便你管理和运行模型。
本文所使用的安装环境为:Docker version 27.5.1 / Docker Compose version v2.32.4 / Nvidia Driver 550.120 / CUDA 12.4
本文仅介绍 Docker Compose 部署方式。关于怎样在 Docker 容器中支持 GPU 调用配置的步骤请参阅 Nvidia 显卡 Docker 配置指引。
部署 LocalAI
使用以下 docker-compose.yaml 来运行 LocalAI,在开始之前请务必参阅 Nvidia 显卡 Docker 配置指引 完成 Docker Engine 配置。
services:
api:
image: localai/localai:latest-gpu-nvidia-cuda-12
deploy:
resources:
reservations:
devices:
- capabilities:
- gpu
count: all
driver: nvidia
environment:
# API Key,你可以删除此项这样调用方就不需要提供 Key 即可访问 LocalAI
- API_KEY=your-api-key
# 代理设置,请把下面的代理连接替换成你自己的,或者删除 HTTP_PROXY / HTTPS_PROXY
- HTTP_PROXY=127.0.0.1:7890
- HTTPS_PROXY=127.0.0.1:7890
- NO_PROXY=127.0.0.0/8,192.168.0.0/16,localhost,tihus.com
- TZ=Asia/Shanghai
- DEBUG=true
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
interval: 1m
timeout: 20m
retries: 5
ports:
- 8080:8080
restart: unless-stopped
volumes:
- ./data/models:/build/models:cached运行容器编排,LocalAI 的整体体积比较惊人(本文选择的镜像体积高达 38.93GB),编排启动可能会需要很长时间。等待容器运行并输出如下日志时代表 LocalAI 启动完成:
8:11PM INF LocalAI API is listening! Please connect to the endpoint for API documentation. endpoint=http://0.0.0.0:8080LocalAI WebUI
模型的安装
输入 http://<Server-IP>:8080 可以打开 LocalAI WebUI:

本文选择 DeepSeek R1 1.5b 作为演示用模型,点击主页的“Gallery”,在打开的页面中搜索 deepseek-r1-distill-qwen-1.5b 即可找到目标模型:
点击模型卡片右下角的“Install”即可开始安装:
等待模型安装完成即可:

模型的管理
点击顶部的“Home”返回主页,此时由于已经安装了模型所以此处会显示已安装的模型列表:
此处唯一可操作的按钮就是删除模型。
LocalAI API
LocalAI 本身只提供了基础的测试工具,同时还导出了 API 以供第三方程序调用。点击 WebUI 顶部的 API 可以打开 LocalAI API 文档:

此 API 为 OpenAI 兼容 API,你可以自行编写程序与其对接,或者在第三方程序如 Dify 中设置对接,此处以 Dify 作为演示。
在 Dify 中,安装 OpenAI-API-compatible 插件用于与 LocalAI 进行连接:
之后点击右上角 头像 - 设置,打开 模型供应商:

点击添加模型,按照下图输入内容,没有展示的部分保持原始值不变:
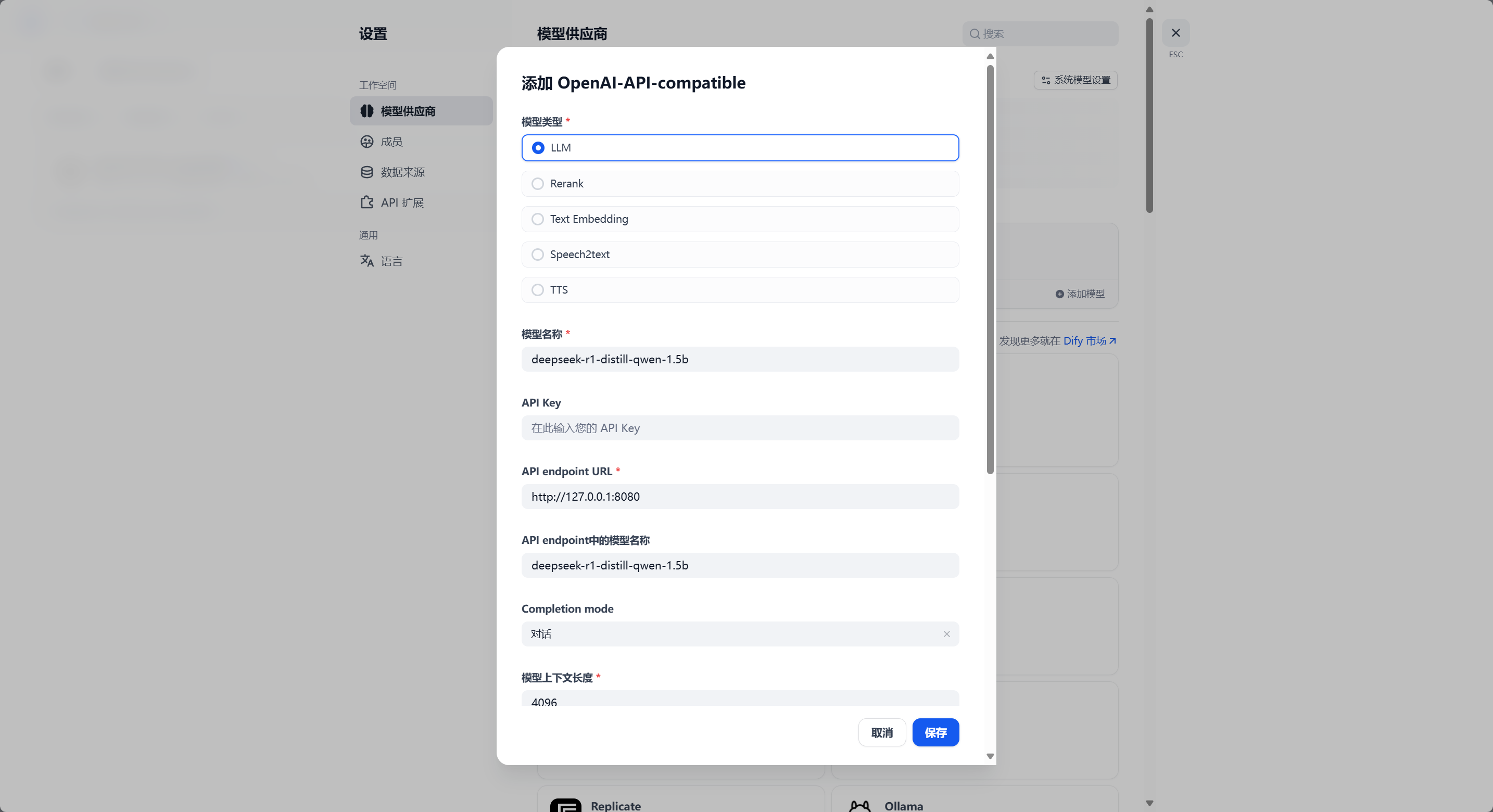
注意,此处我的 API endpoint URL 的设置是不正确的,你应当把这个链接修改为 http://<LocalAI所在的设备IP>:8080/v1。
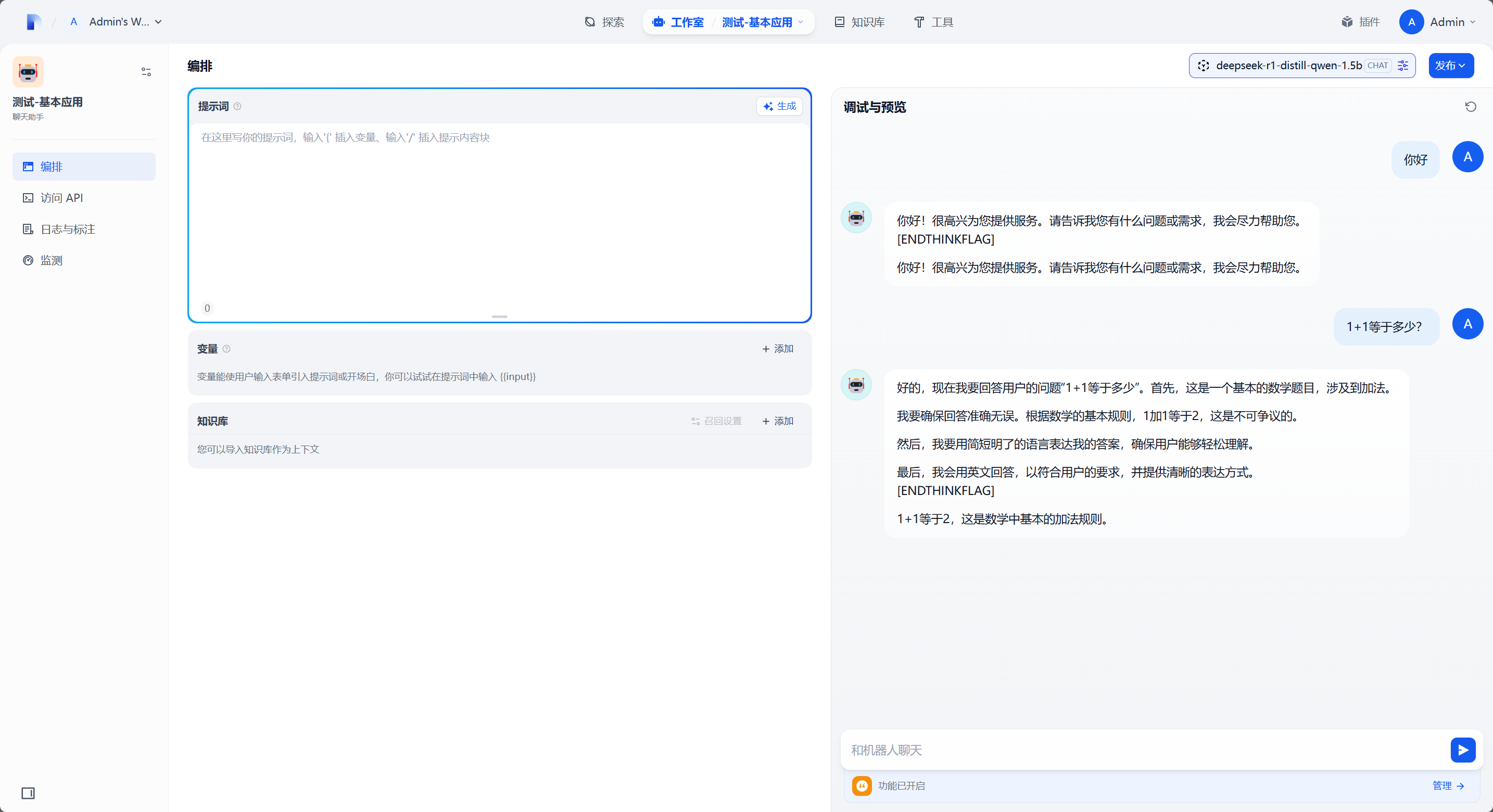
之后新建应用进行测试即可,Dify 的 OpenAI-API-compatible 插件似乎目前还不支持 R1 的思考过程,所以会冒出一些不该出现的句子。另外,第一次运行刚下好的模型时 LocalAI 会进行一些环境的初始化操作,耗时会有些久。待 LocalAI 初始化完成之后回复问题就会快的多了。
至此 LocalAI 的完整部署使用指引结束。整个部署和使用过程意外的顺利,比起 Xinference 要顺利多了......