WaterCrawl:高效网站内容结构化工具
在先前的文章中,我介绍过如何部署和使用 Firecrawl。但是 Firecrawl 的使用相对繁琐,需要自己构建镜像,同时 Firecrawl 的商业版和社区版之间的差别实在是太大,如果不是 Dify 知识库默认只支持它,我大概根本不会想去介绍它。
诶!好消息是,Dify v1.2.0 中新增了对 WaterCrawl 的支持,听名字就能知道这个工具很明显就是冲着 Firecrawl 来的。WaterCrawl 有官方镜像可以很方便的本地部署,同时也有着更方便使用的后台管理界面,也支持自定义 User Agent 等常用操作。
在开始之前
目前 WaterCrawl 项目处于刚起步阶段,无论是名称的选择还是选择在 Dify 中提供集成支持,都在体现这个团队想要借助现有品牌势力快速发展。当然与 Firecrawl 相同的是,WaterCrawl 有自己的商业版,截至本文写作时,WaterCrawl 的商业版和社区版除部分用户管理方面的配置外并无太大区别。
但对比 Firecrawl,WaterCrawl 使用成熟的 Scrapy 框架,支持配置 UA、robots.txt、请求速率限制等基础功能,这些已经把 Firecrawl 的社区版按在地上打了。倒不是说 Firecrawl 不能设置这些内容,而是 Firecrawl 需要商业版付费才能设置这些,社区版甚至连管理界面都没有,只能说还是一家独大太久了......
本文所使用的安装环境为:Docker version 27.5.1 / Docker Compose version v2.32.4。
Docker 部署
WaterCrawl 有官方镜像,现在项目还刚处于起步阶段,部署具体方式可能会出现大幅变化。这里使用官方部署方式,但是会选择性介绍部分可修改的配置。
运行以下命令可以直接启动官方镜像:
git clone https://github.com/watercrawl/watercrawl.git
cd watercrawl
cd docker
cp .env.example .env
docker compose up -d实际上就是下载了官方仓库并使用其中的镜像编排文件,所以我们只需关心 docker-compose.yaml 和 .env 文件。
在 docker-compose.yaml 文件中,只需要按需修改 minio 和 db 服务中的 volumes 设定即可。WaterCrawl 只使用这两个服务来存储自身数据。
在 .env 文件中则主要存储 WaterCrawl 系统配置相关的内容,其中以下配置项可以按需进行调整,没提到的配置项不需要修改或者按需修改即可:
# 通用配置
# ---------------
# Nginx 服务端口 (default: 80),WebUI 和 API 都使用这个端口。
NGINX_PORT=80
# Django 配置
# -------------------
# Django 会话加密密钥 - 绝对不要把此密钥泄露出去!
# 你可以使用 `openssl rand -base64 32` 命令来随机生成一个新的密钥。
SECRET_KEY="USE-YOUR-OWN-KEY"
# Debug 模式,生产环境部署时改为 False
DEBUG=True
# 用于 CORS 和重定向的前端 URL,在邀请邮件和链接中也会使用此 URL。
FRONTEND_URL=http://localhost
# ------------
# 中间有些配置无需调整,比如用户注册管理之类的在社区版不可用。
# ------------
# Scrapy 配置
# --------------
# User Agent
SCRAPY_USER_AGENT="WaterCrawl/0.5.0 (+https://github.com/watercrawl/watercrawl)"
# 遵守 robots.txt 规则
SCRAPY_ROBOTSTXT_OBEY=True
# 并发请求数
SCRAPY_CONCURRENT_REQUESTS=16
# 下载请求之间的时间 (秒)
SCRAPY_DOWNLOAD_DELAY=0
# 单个域名并发请求数
SCRAPY_CONCURRENT_REQUESTS_PER_DOMAIN=4
# 单个 IP 并发请求数
SCRAPY_CONCURRENT_REQUESTS_PER_IP=4
# 启用 cookies
SCRAPY_COOKIES_ENABLED=False
# 允许 HTTP 缓存
SCRAPY_HTTPCACHE_ENABLED=True
# HTTP 缓存过期时间 (秒)
SCRAPY_HTTPCACHE_EXPIRATION_SECS=3600
# HTTP 缓存目录
SCRAPY_HTTPCACHE_DIR=httpcache
# Scrapy 日志等级
SCRAPY_LOG_LEVEL=ERROR
# 功能配置
# ------------
# 最大爬取深度 (-1 即无限深度爬取)
MAX_CRAWL_DEPTH=-1
# 保存用户使用历史
CAPTURE_USAGE_HISTORY=True
# 前端配置
# ---------------
# API base URL,可以是绝对 URL 或相对 URL,比如 http://localhost/api 或 /api,如果使用 Dify 集成则不能修改此项
API_BASE_URL=/api确认配置无误后,使用 docker compose up -d 命令可以启动容器编排,初次启动可能会等待一段时间。等待 app 服务日志输出 Listening at: http://0.0.0.0:9000 (9) 字样即代表系统启动完成。
WebUI 简介
当你部署完成以后,访问 http://<Server-IP>:80(如果你修改了 .env 的 NGINX_PORT 则为对应端口)即可访问 WaterCrawl 后台页面:
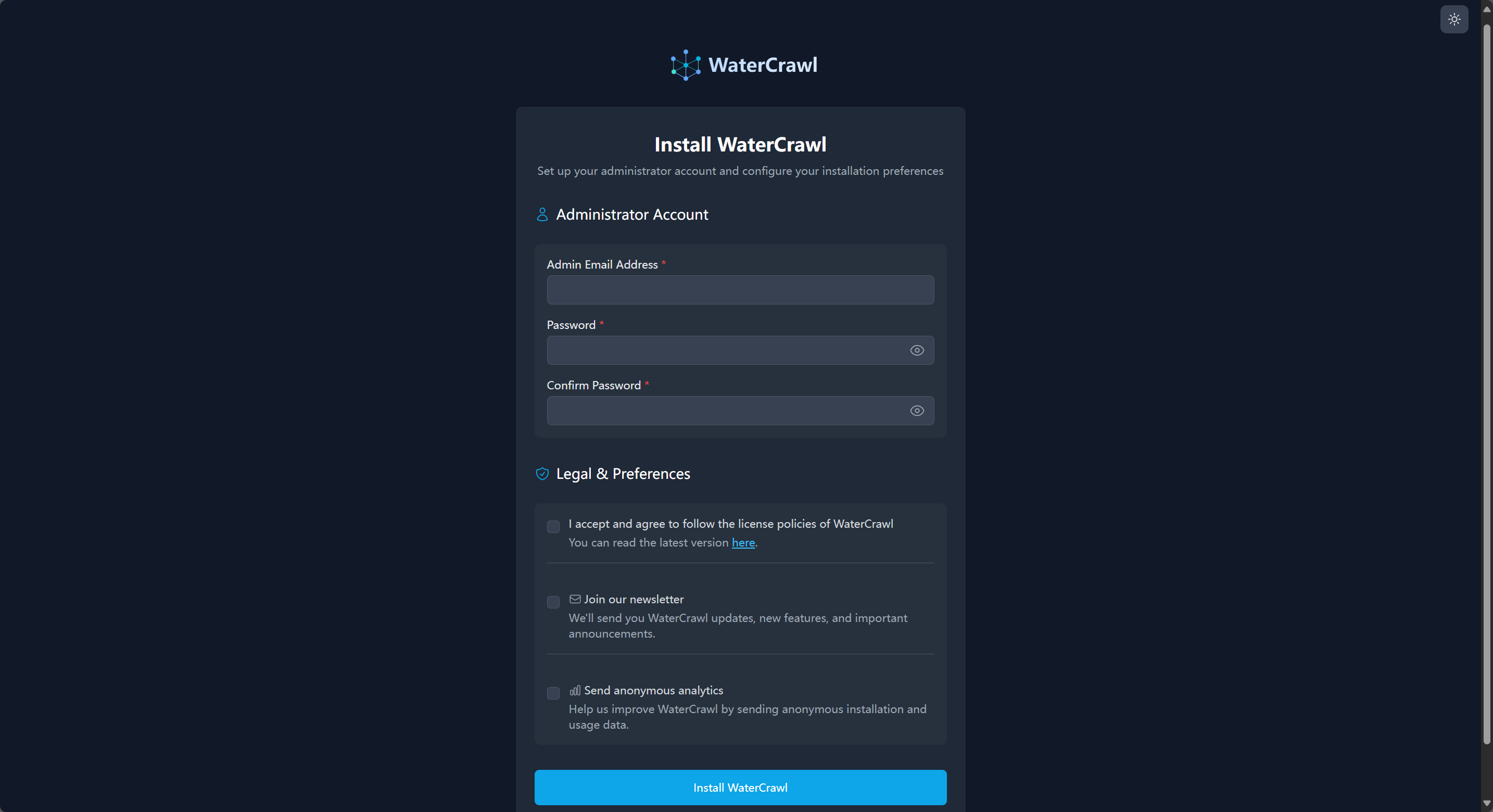
初次打开会进入这个管理员初始化界面,上面是登陆凭据设置,填入登陆邮箱和密码,下面的三个复选框分别是:
同意并遵守 WaterCrawl 协议政策,现在指向的是 MIT 开源协议,未来应该会替换成 WaterCrawl 自己的协议。
【可选】订阅 WaterCrawl 新闻邮件,若勾选此项则管理员邮箱需要是能正常接收邮件的邮箱。
【可选】发送匿名统计分析信息,勾选此项会发送一些系统软硬件分析信息给 WaterCrawl 来帮助他们改善自己的软件。
确认信息后点击最底部的按钮即可进入 WaterCrawl 后台管理页面:
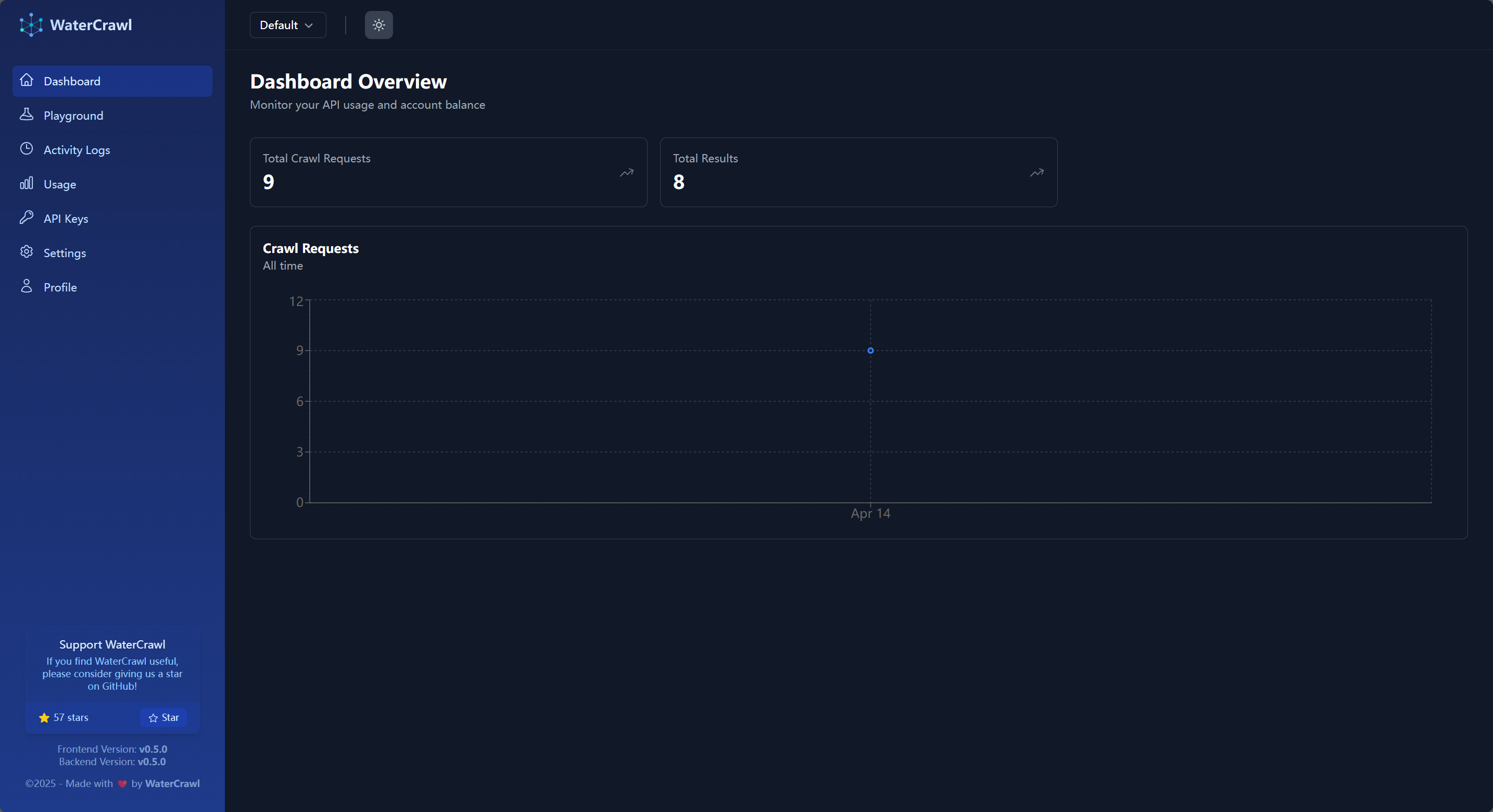
左侧依次是:
Dashboard(主仪表板):当前账号下概略信息显示,社区版可以理解为系统信息概略显示
Playground(测试场):可以对想要进行爬取的 URL 进行抓取测试,所有 WaterCrawl 支持的功能都可以在这里进行配置
Activity Logs(活动记录):账号历史爬取 URL 的记录
API Keys:API 调用所需的 API Key 管理页面
Usage / Settings / Profile 中的功能在社区版中均无效
在这些页面中,常规用途下测试场页面是最常用到的,你可以在这里配置爬取测试,然后将 WaterCrawl 集成到你的应用中。
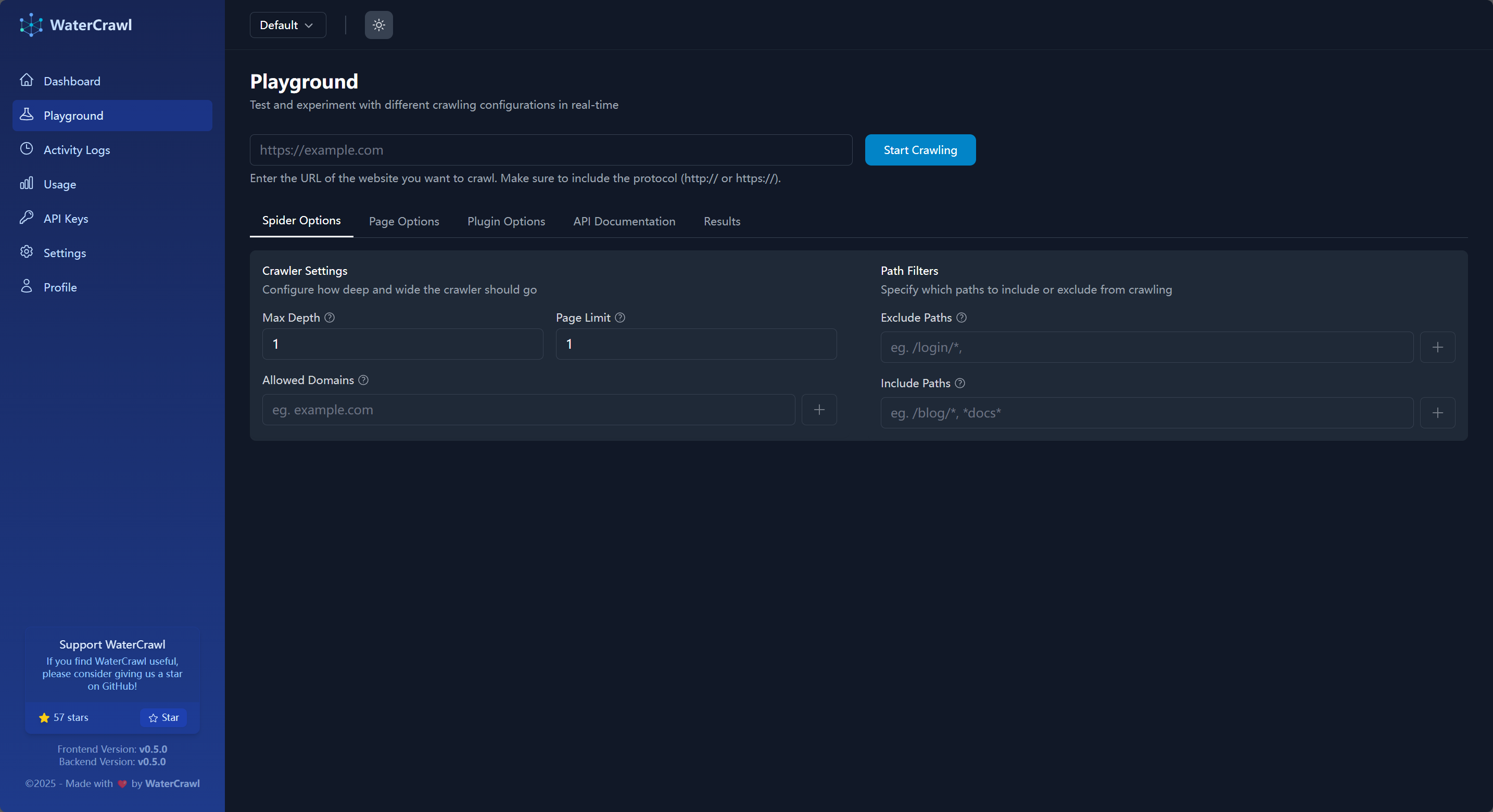
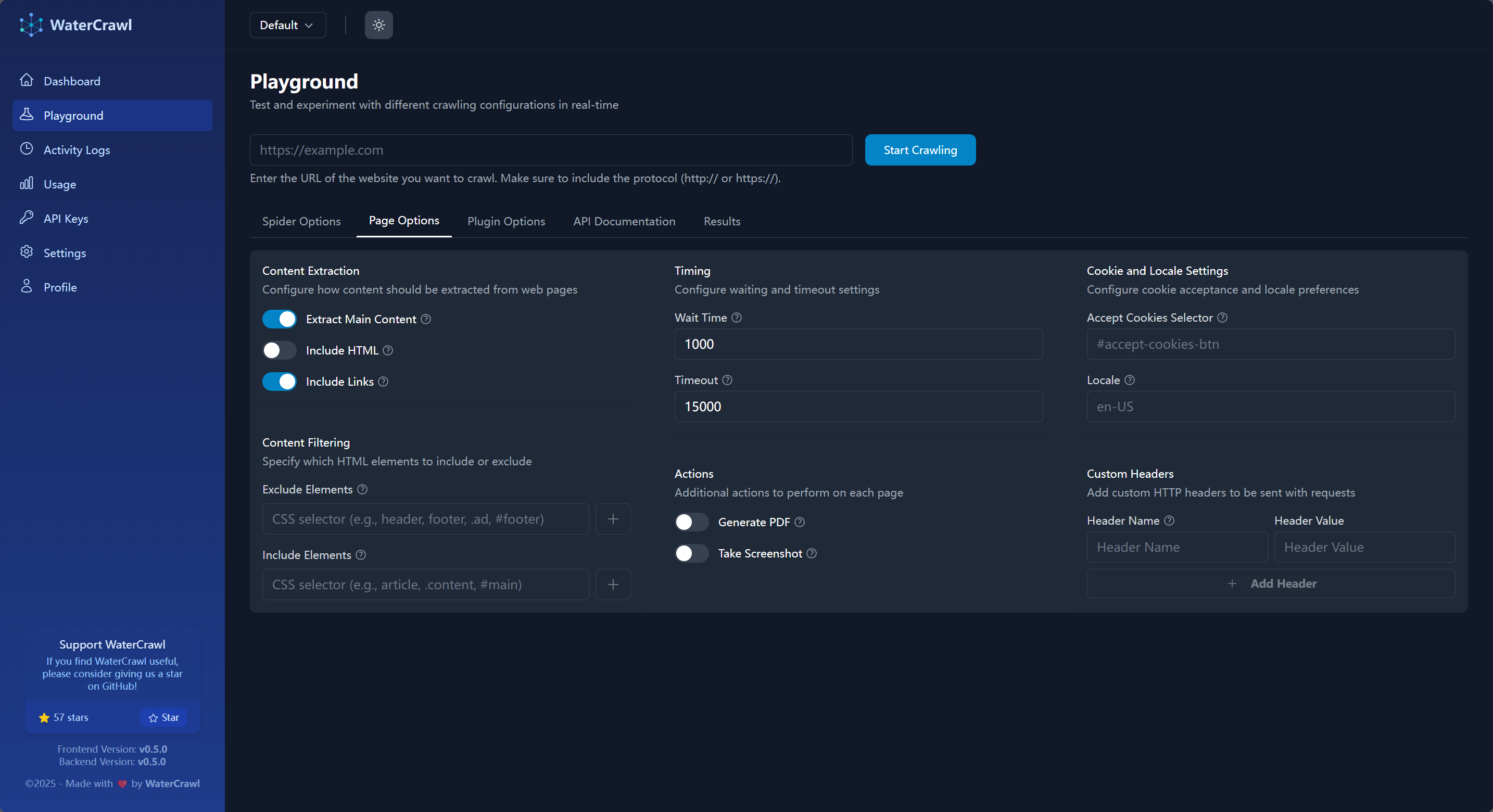
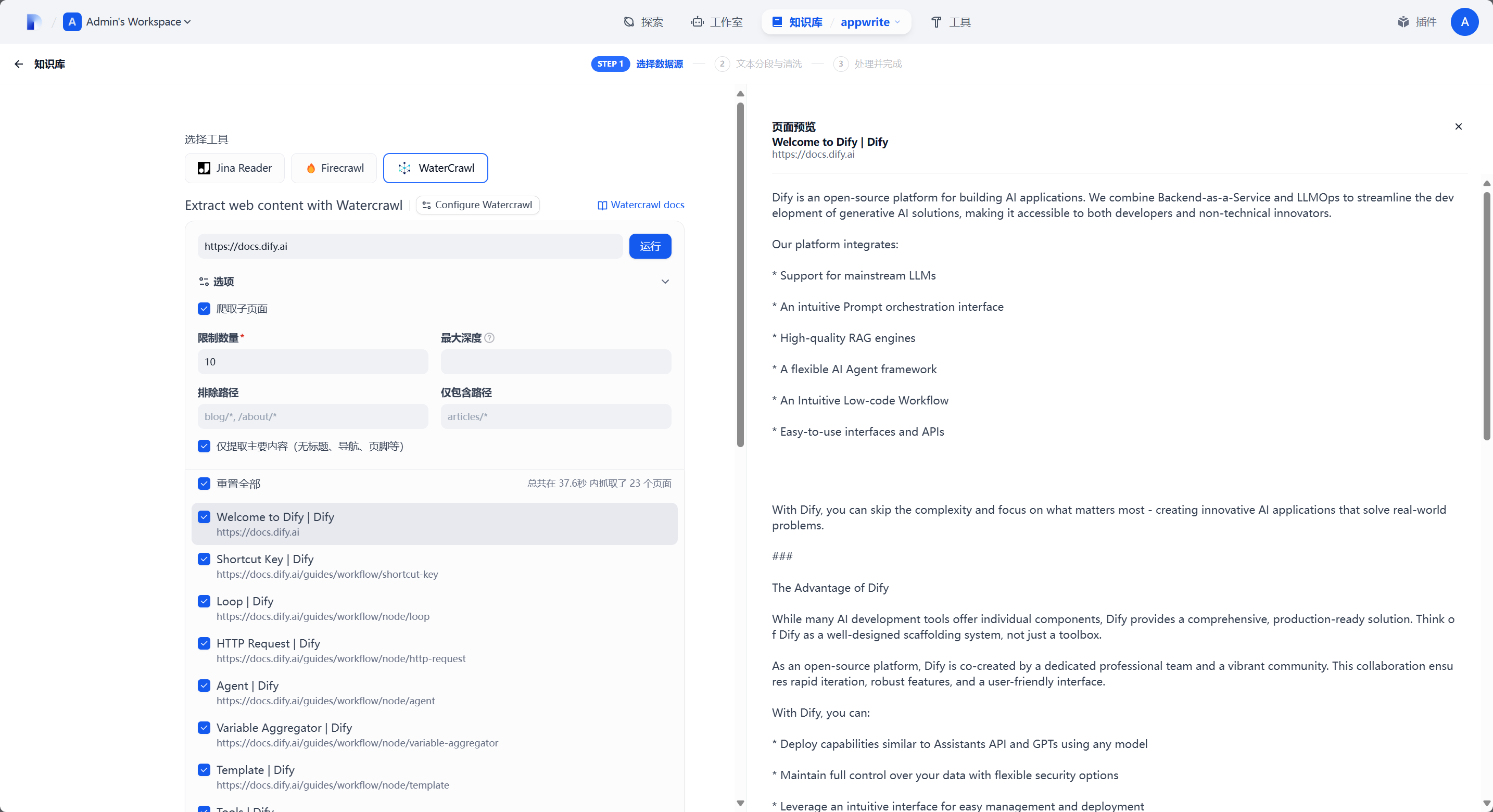
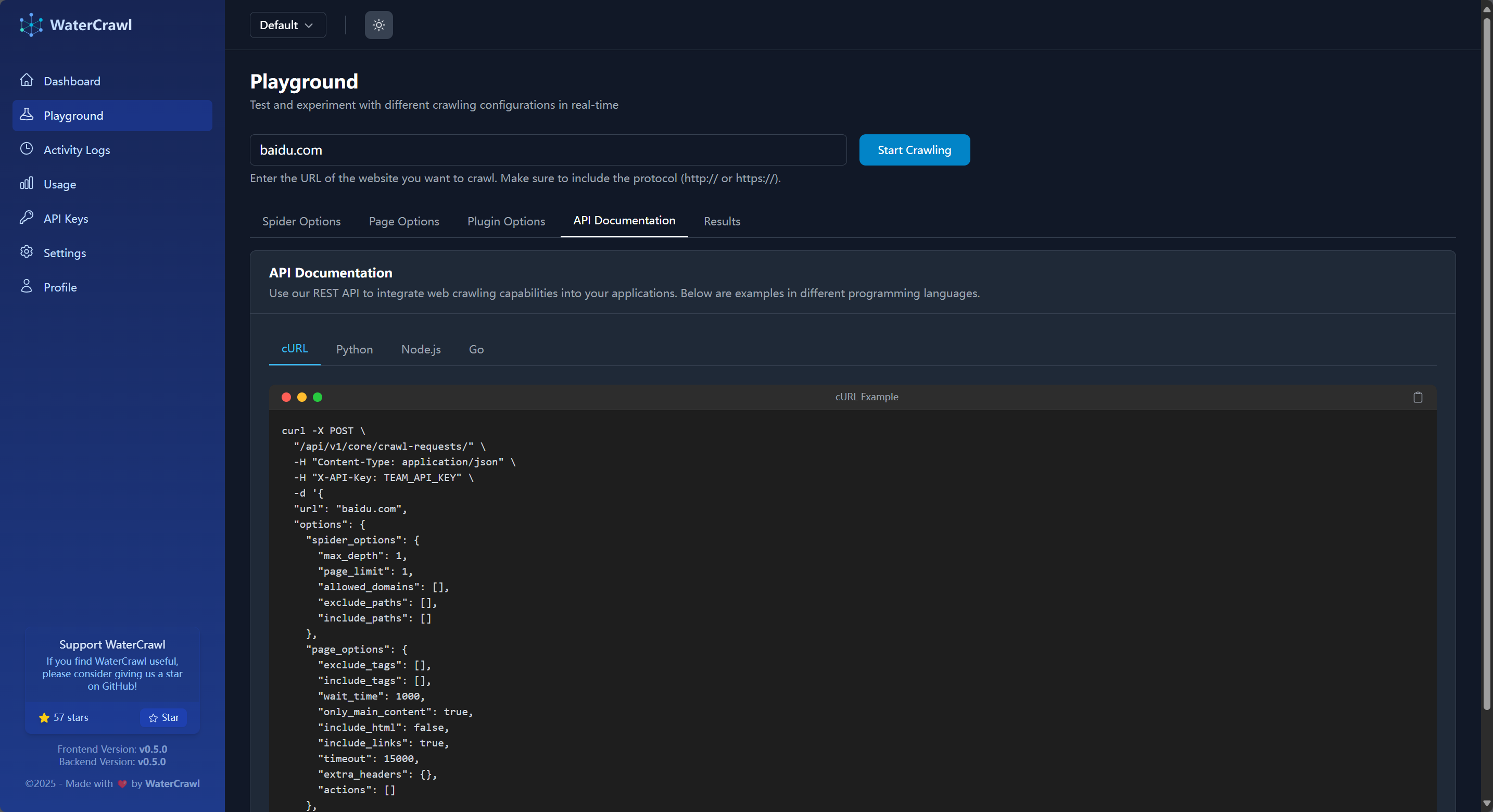
在测试场页面,你可以预设你要抓取的 URL,在 Spider Options 和 Page Options 中设置你要爬取的具体参数比如是否爬取子页面、爬取子页面的深度、UA / Locale 设置、结果格式转换等等功能,当你测试完成之后,在 API Documentation 页面你就可以看到具体的 API 接口调用示例:
在 Dify 中使用
在 Dify 中使用集成非常简单,首先前往 WaterCrawl 的 API Keys 页面:
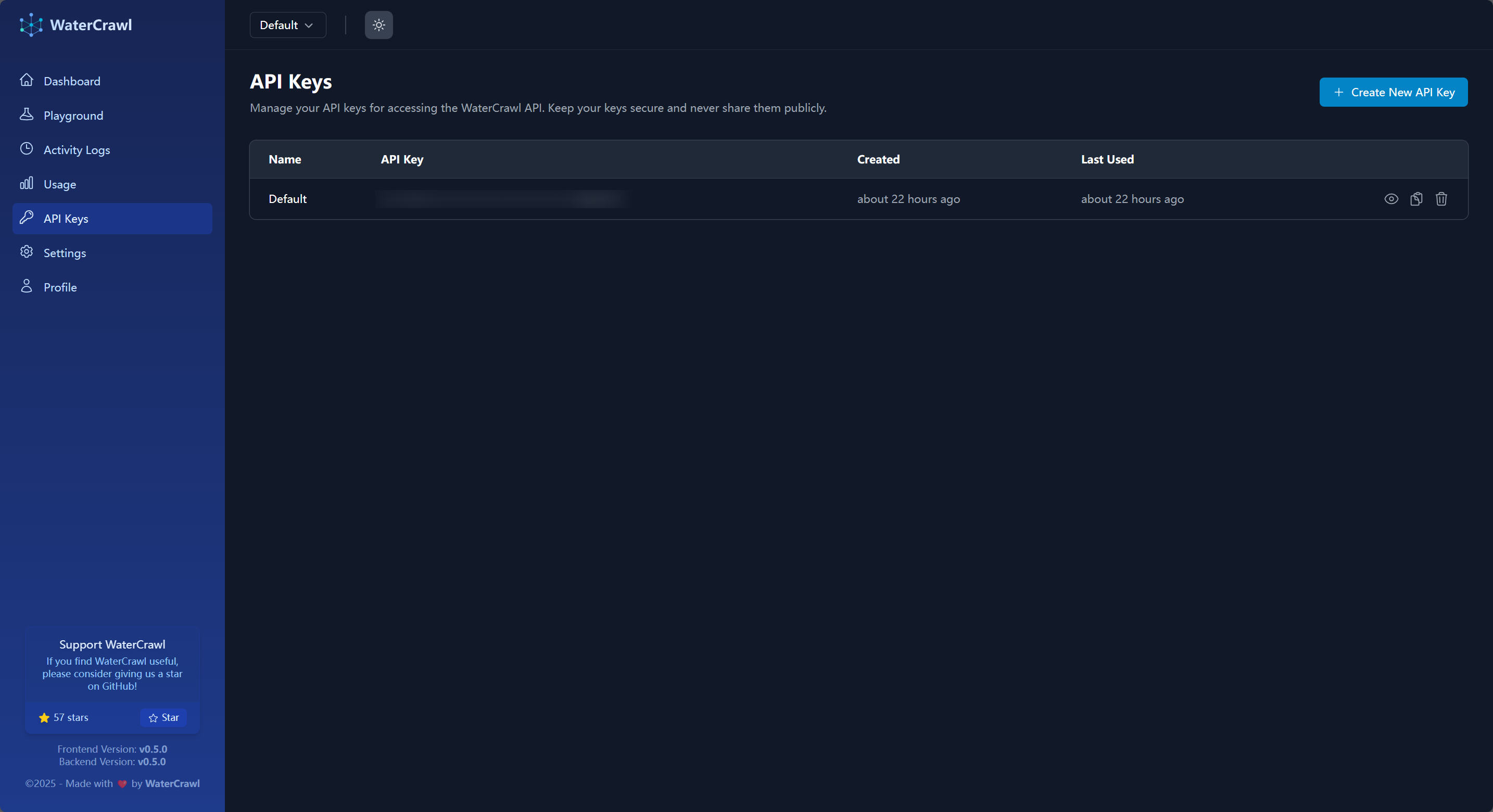
在这里有可能你点击后面的 复制 按钮时提示复制失败,此时可以点击 眼睛 按钮来显示 API Key 之后手动复制即可。
转到 Dify - 头像 - 设置 - 数据来源:
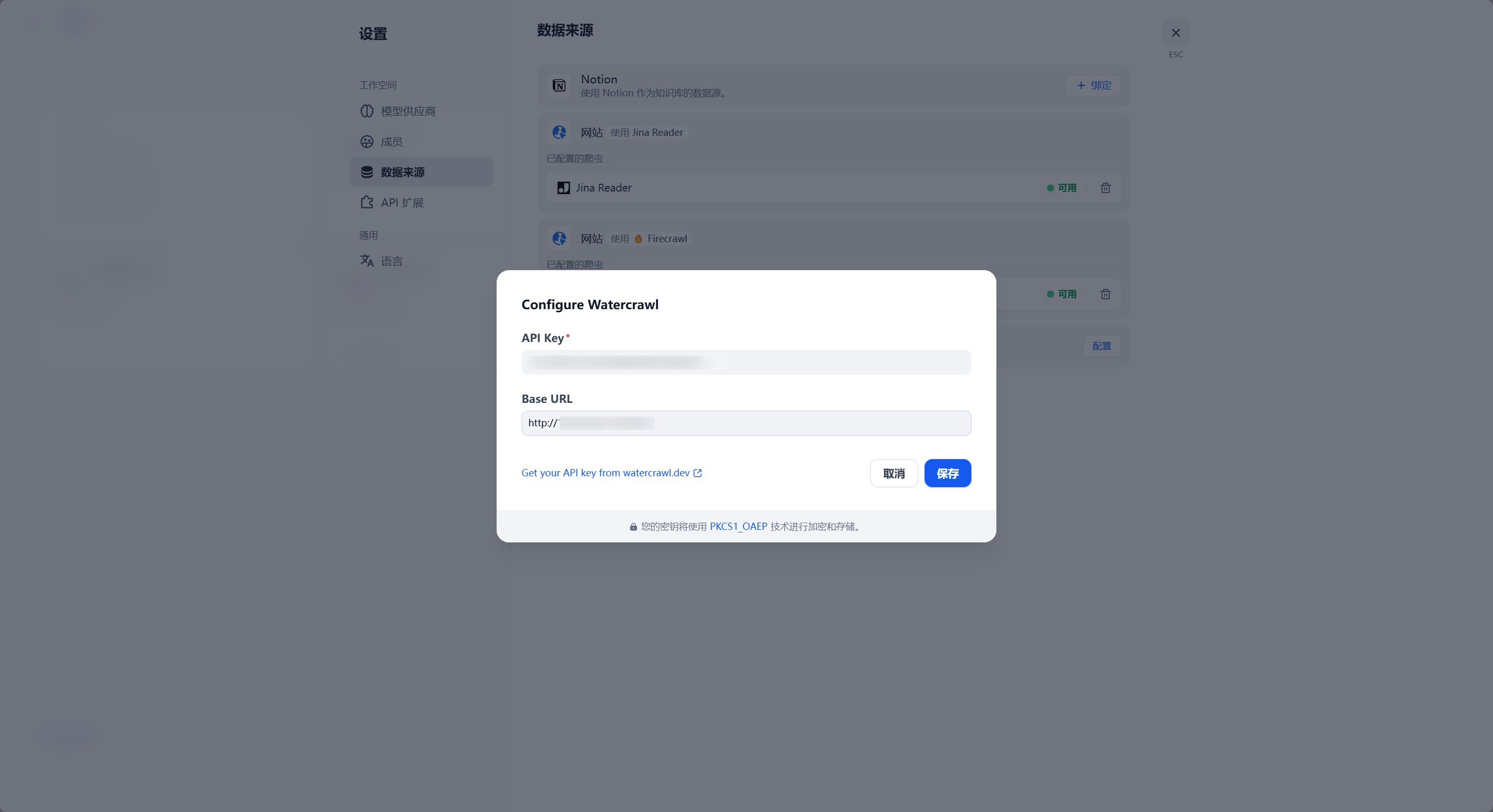
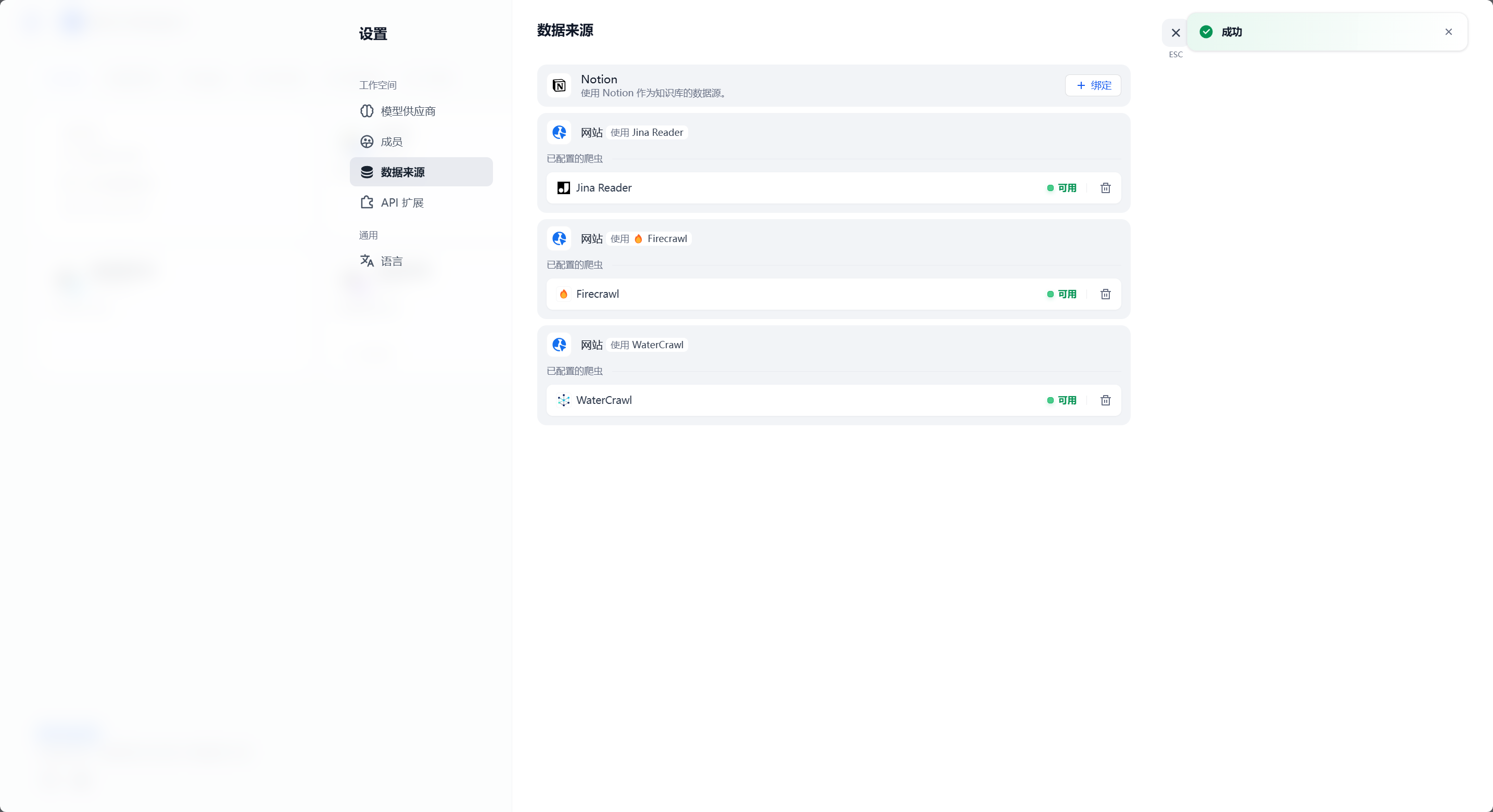
之后在知识库处就可以像 Firecrawl 一样使用了: