Ollama 部署完全指引
工欲善其事,必先利其器。在继续讲 Dify 之前,先插个小短篇讲讲怎么在 Docker 上安装并部署 Ollama 吧。
在开始之前
本教程将会使用的安装环境:
Ubuntu Server 24 @ CPU 3.3Ghz x 4 / RAM 12GiB
RTX 3050 Mobile / 4G
Docker version 27.5.1 / Docker Compose version v2.32.4
你可以根据自己的需求对硬件配置和软件配置进行适当调整。另外,此教程中还使用 1Panel 来简化服务器的安装、维护与状态监看。1Panel 是一个开源且轻量化的服务器管理面板,具体文档和安装指引请参照官方文档,本文将不会深入介绍。有关于 Ubuntu Server 的安装可以参照《Ubuntu Server 安装教程》。
注意,Ollama 对于显卡有兼容性要求,你可以查看官方的 GPU 支持列表,确保你的显卡在支持列表范围内再继续。
安装显卡驱动
对于 AMD 显卡用户,可跳过此部分,你需要使用到 ROCm 来实现对 LLM 运行的支持,具体可以参照官方文档(全英文)。
对于 Ubuntu Server 来说,这步是非常简单的,简单到只要你的显卡不是太邪门,只需要两行命令即可完成相关配置。
注意:PVE直通下,如果你不确定你的显卡完全没有被系统调用,则不要勾选“全部功能”。ESXi 下则需注意 ESXi6.7 下英伟达显卡驱动不能够被正常识别,推荐使用 ESXi7 及以上版本。
SSH 连接到服务器,输入 ubuntu-drivers devices ,设备没有问题的话可以看到类似如下输出:
== /sys/devices/pci0000:00/0000:00:10.0 ==
modalias : pci:v000010XXd00002FT2ox000079GEsd00003THZbc28sc00i00
vendor : NVIDIA Corporation
model : GA107BM [GeForce RTX 3050 Mobile]
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : nvidia-driver-550 - distro non-free recommended
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-550-open - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin前面可能会有一些 Error 或者 Warning,在当前 Ubuntu Server 24 中是正常现象,忽略即可。
此处的输出给出了推荐驱动列表,末尾有 recommended 的是自动安装功能所使用的驱动。你有两种方式可以安装驱动:
对驱动版本没有要求或者不知道自己要用什么驱动,输入
sudo ubuntu-drivers autoinstall来自动安装驱动。对驱动版本有要求,输入
sudo apt install nvidia-driver-<version>来安装特定版本驱动。
那么这里默认推荐的驱动版本并没有什么问题,可以直接运行 sudo ubuntu-drivers autoinstall 来让 Ubuntu 自动安装显卡驱动,此过程可能需要个几分钟。等待显卡驱动安装完成之后,重新启动系统,在命令行运行 nvidia-smi ,出现如下结果即显卡驱动顺利安装完成。
ubuntu@test:~$ nvidia-smi
Wed Mar 5 05:26:54 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3050 ... Off | 00000000:00:10.0 Off | N/A |
| N/A 45C P8 7W / 60W | 2MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+nvidia-smi 报错请参照文末
拓展内容 - nvidia-smi 报错
安装 Docker & 1Panel
这里偷个懒,直接安装 1Panel 让它顺手给 Docker 安装一下......
必须要说的是,1Panel 的安装脚本处理非常完善,充分考虑到了国内外的网络问题。如果你只需要安装 Docker & Docker Compose 而不需要 1Panel 的情况下,可以自行修改安装脚本注释掉 1Panel 的安装部分,比直接使用 Docker 官方的安装脚本要省心多了。
本文后续会同时讲解如何通过命令行和 1Panel 来部署和使用 Ollama,请放心继续阅读!
这里使用官方的安装命令快速安装和部署 1Panel:
[1Panel Log]:
[1Panel Log]: =================感谢您的耐心等待,安装已完成==================
[1Panel Log]:
[1Panel Log]: 请使用您的浏览器访问面板:
[1Panel Log]: 外部地址: http://<IPv6 地址>:<端口>/<安全入口>
[1Panel Log]: 内部地址: http://<IPv4 地址>:<端口>/<安全入口>
[1Panel Log]: 面板用户: <用户名>
[1Panel Log]: 面板密码: <密码>
[1Panel Log]:
[1Panel Log]: 官方网站: https://1panel.cn
[1Panel Log]: 项目文档: https://1panel.cn/docs
[1Panel Log]: 代码仓库: https://github.com/1Panel-dev/1Panel
[1Panel Log]: 前往 1Panel 官方论坛获取帮助: https://bbs.fit2cloud.com/c/1p/7
[1Panel Log]:
[1Panel Log]: 如果您使用的是云服务器,请在安全组中打开端口 <端口>
[1Panel Log]:
[1Panel Log]: 为了您的服务器安全,离开此屏幕后您将无法再次看到您的密码,请记住您的密码。
[1Panel Log]:
[1Panel Log]: ================================================================1Panel 安装过程中的端口、安全入口、用户名和密码全部为可配置项目,根据你自己的需求进行配置即可。
安全性警告:1Panel 是服务器管理面板,拥有极高的权限,请不要将 1Panel 的管理端口无防护的开放到公网,如果确有需求,请在面板中设置足够复杂的用户名和密码组合,并开启 2FA 以增加安全性!
访问 http://<IPv4 地址>:<端口>/<安全入口> 即可打开 1Panel 的登陆页面,输入用户名和密码,勾选同意协议即可登录:
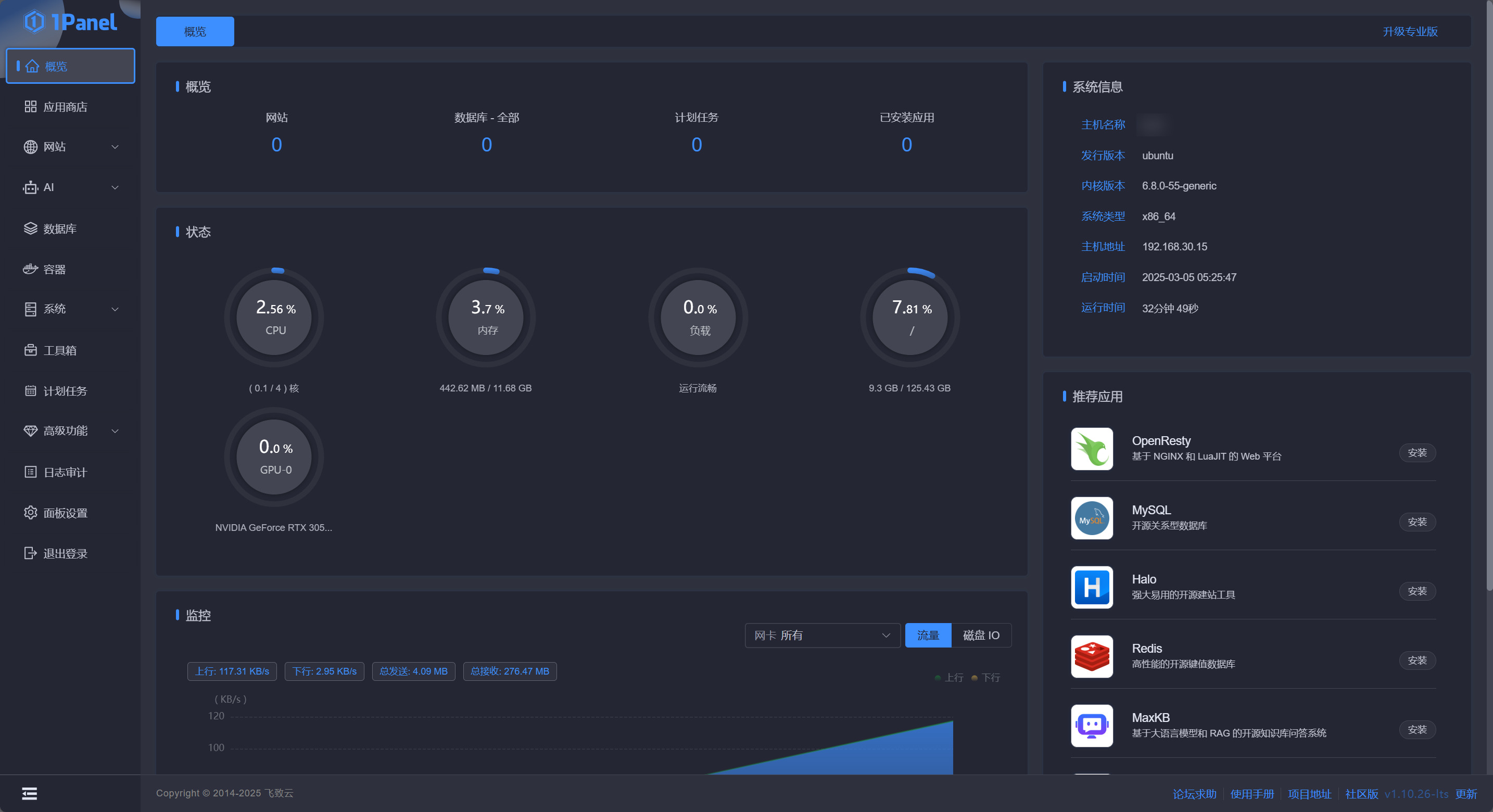
在概览中,状态栏已经可以看到 GPU 的负载状态了,点击左侧 AI - GPU 监控 可以看到更详细的 GPU 负载信息:
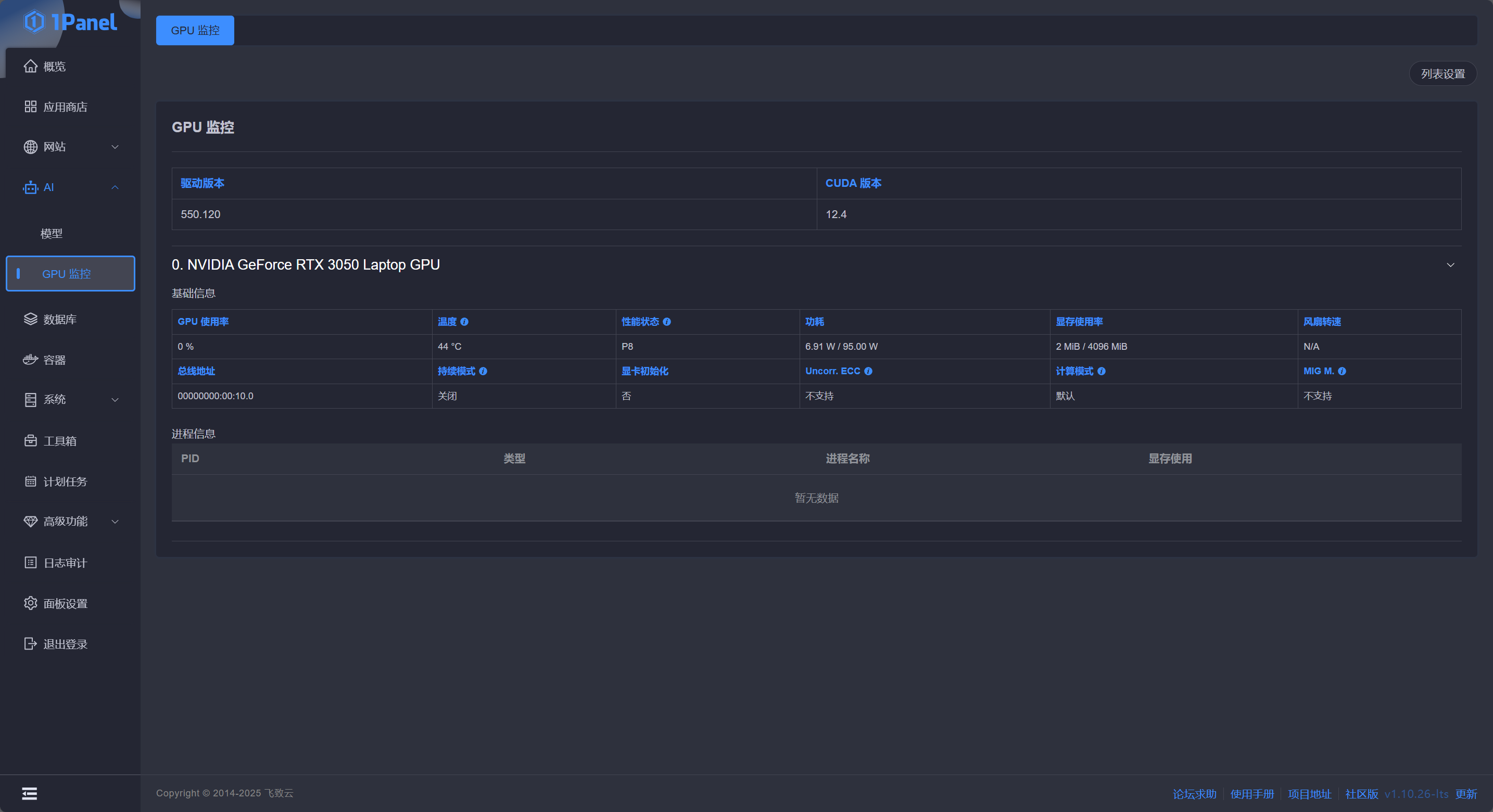
命令行监控 GPU 状态请参照文末
拓展内容 - 命令行监控 GPU 使用情况
部署 Ollama
在部署之前
AMD 显卡用户注意,你们无需安装以下内容,而是需要首先配置 ROCm 运行环境,然后依据 Ollama 官方部署文档 ,使用特定的
ollama/ollama:rocm镜像才能启动 Ollama。
要在 Docker 上部署 Ollama,首先需要安装 Nvidia Container Toolkit。
SSH 连接服务器,运行下列命令添加仓库配置:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update仓库配置添加完成后运行 sudo apt-get install nvidia-container-toolkit 即可安装 Nvidia Container Toolkit。
安装完成后运行 sudo nvidia-ctk runtime configure --runtime=docker 来对 Docker 进行配置,让其能够调用 GPU 资源。
上述命令运行完成之后,运行 sudo systemctl restart docker 来重启 Docker Engine 应用配置。
1Panel 部署
如果你没有安装 1Panel,请跳转到下一节学习如何通过 Docker Compose 部署
请务必完成
在部署之前章节的内容后再进行 Ollama 的部署
点击左侧 AI - 模型,1Panel 会提示你“未检测到 Ollama ,请进入应用商店点击安装!”,根据提示点击链接即可跳转到应用商店进行安装:
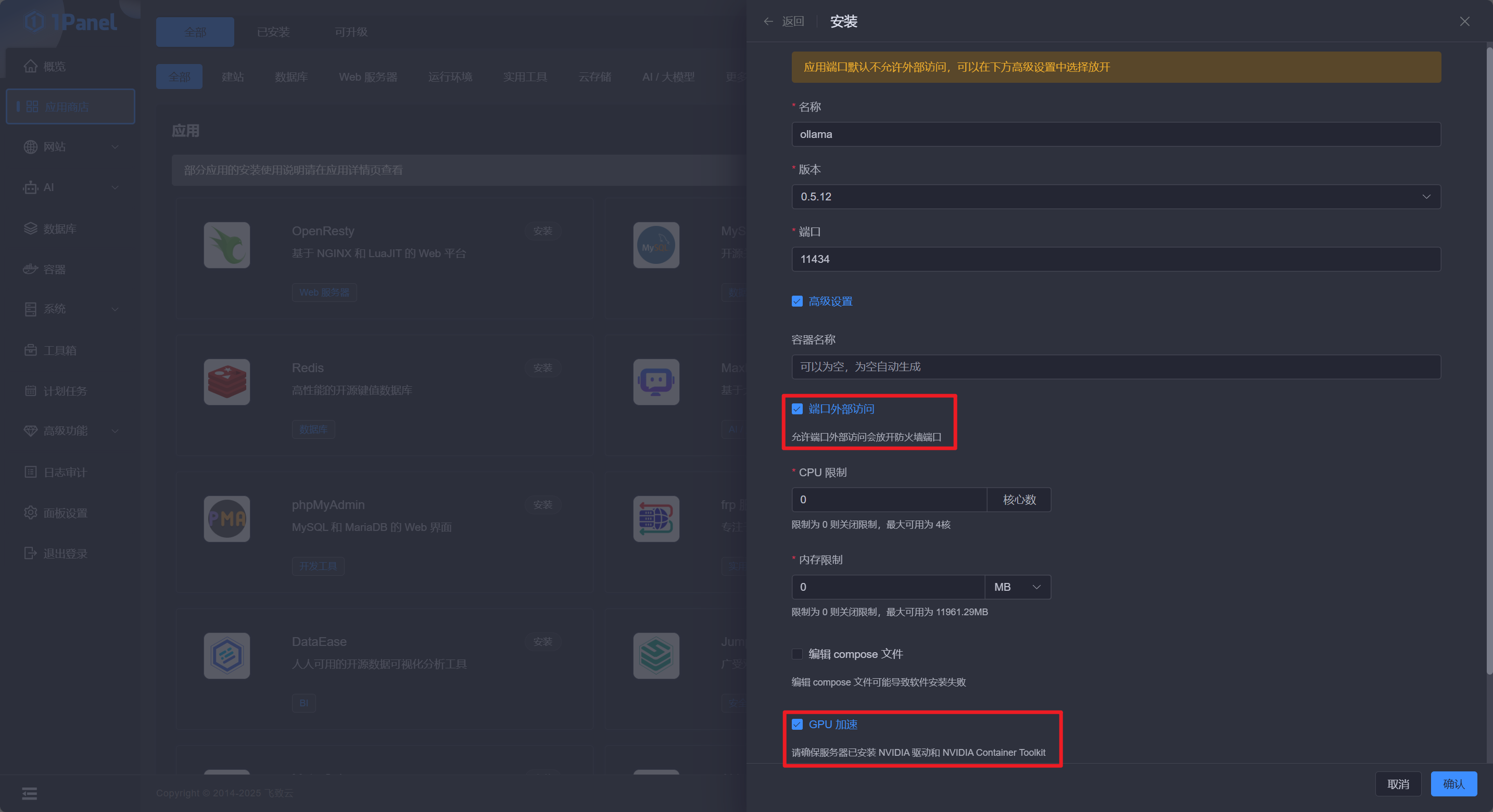
勾选 端口外部访问 和 GPU 加速 ,点击 确认 即可自动跳转到安装页面,等待安装状态变成“运行中”即代表安装完成:
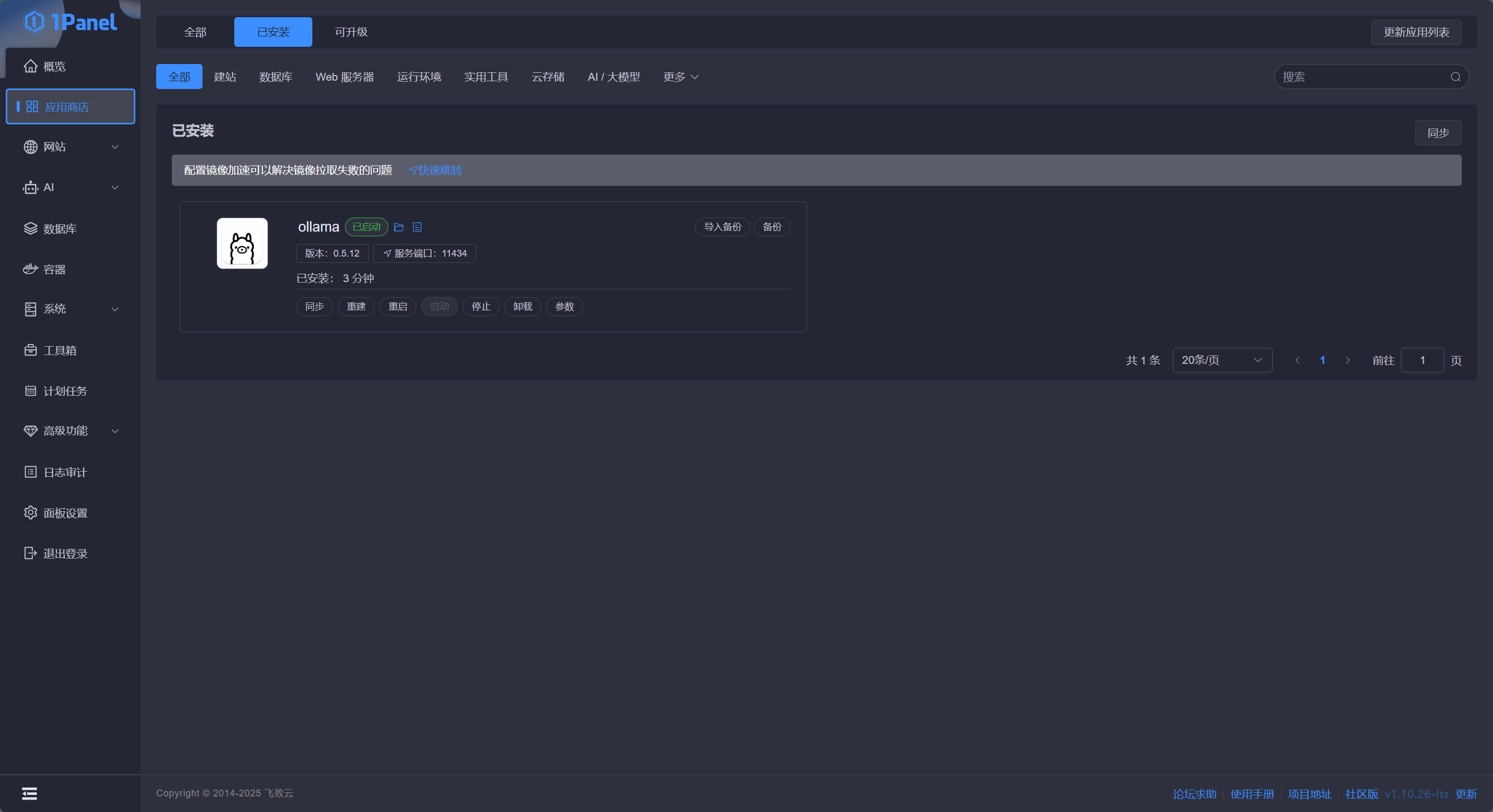
此时点击侧边 AI - 模型 即可打开 Ollama 配置页面:
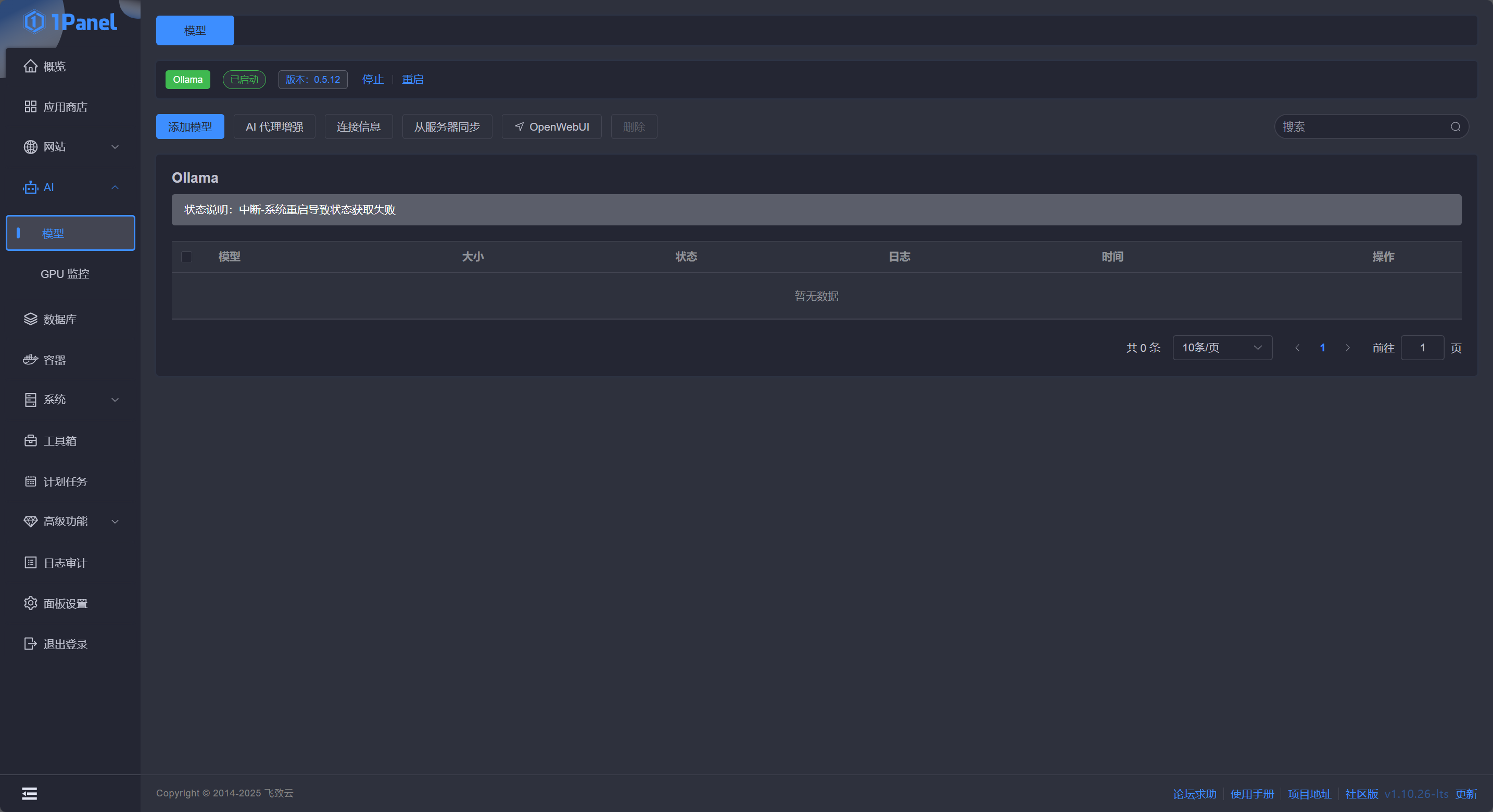
Docker Compose 部署
如果你已通过 1Panel 部署则此章节可跳过
请务必完成
在部署之前章节的内容后再进行 Ollama 的部署
通过 Docker Compose 部署所需的 docker-compose.yaml 的内容如下:
services:
core:
container_name: ollama
deploy:
resources:
reservations:
devices:
- capabilities:
- gpu
count: all
driver: nvidia
environment:
- TZ=Asia/Shanghai
image: ollama/ollama:0.6.0
ports:
- 11434:11434
restart: unless-stopped
volumes:
- ./data:/root/.ollama
保存编排文件后,运行 docker compose -p ollama up -d 即可启动编排。待编排启动后,运行 sudo docker exec -it ollama /bin/bash 即可与 Ollama 容器进行交互,运行 ollama -v ,出现如 ollama version is 0.5.12 的回复即代表 Ollama 正常启动。
部署 DeepSeek 模型
在 Ollama 中运行模型,大致分为2步,首先是从 Ollama Library 找到自己想要运行的模型,然后就是在 Ollama 中运行它。以 DeepSeek-R1-1.5b 版本为例,Ollama Library 的页面长这个样子:
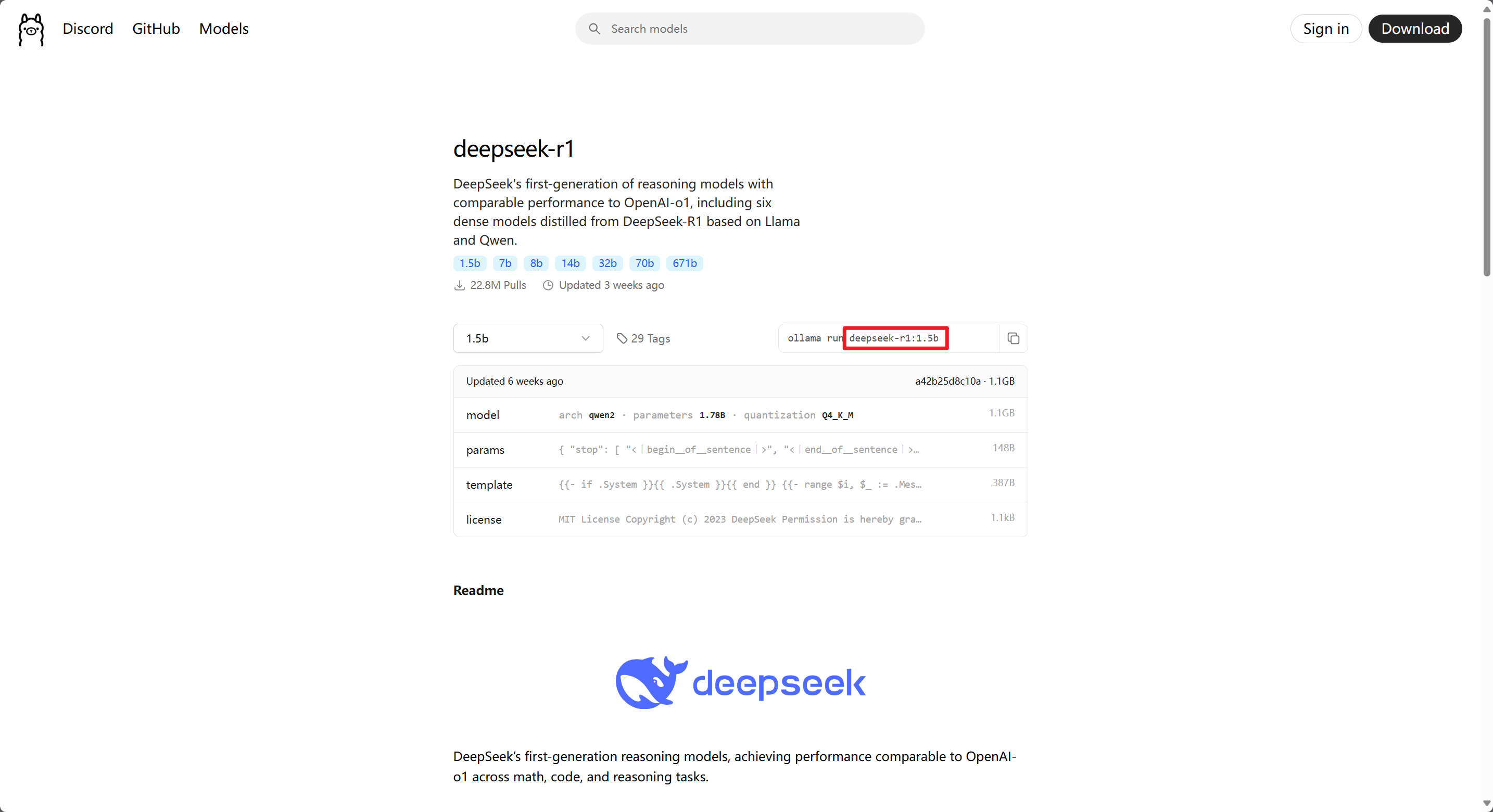
在红框左侧可以切换当前模型的不同参数水平或者说版本,红框处的命令用于命令行运行该模型,而红框内的内容即为模型的具体名称。
通过 1Panel 运行
要运行 DeepSeek-R1-1.5b,通过 1Panel 运行只需要在侧边点击 AI - 模型 - 添加模型,然后输入模型的具体名称点击 添加 即可。
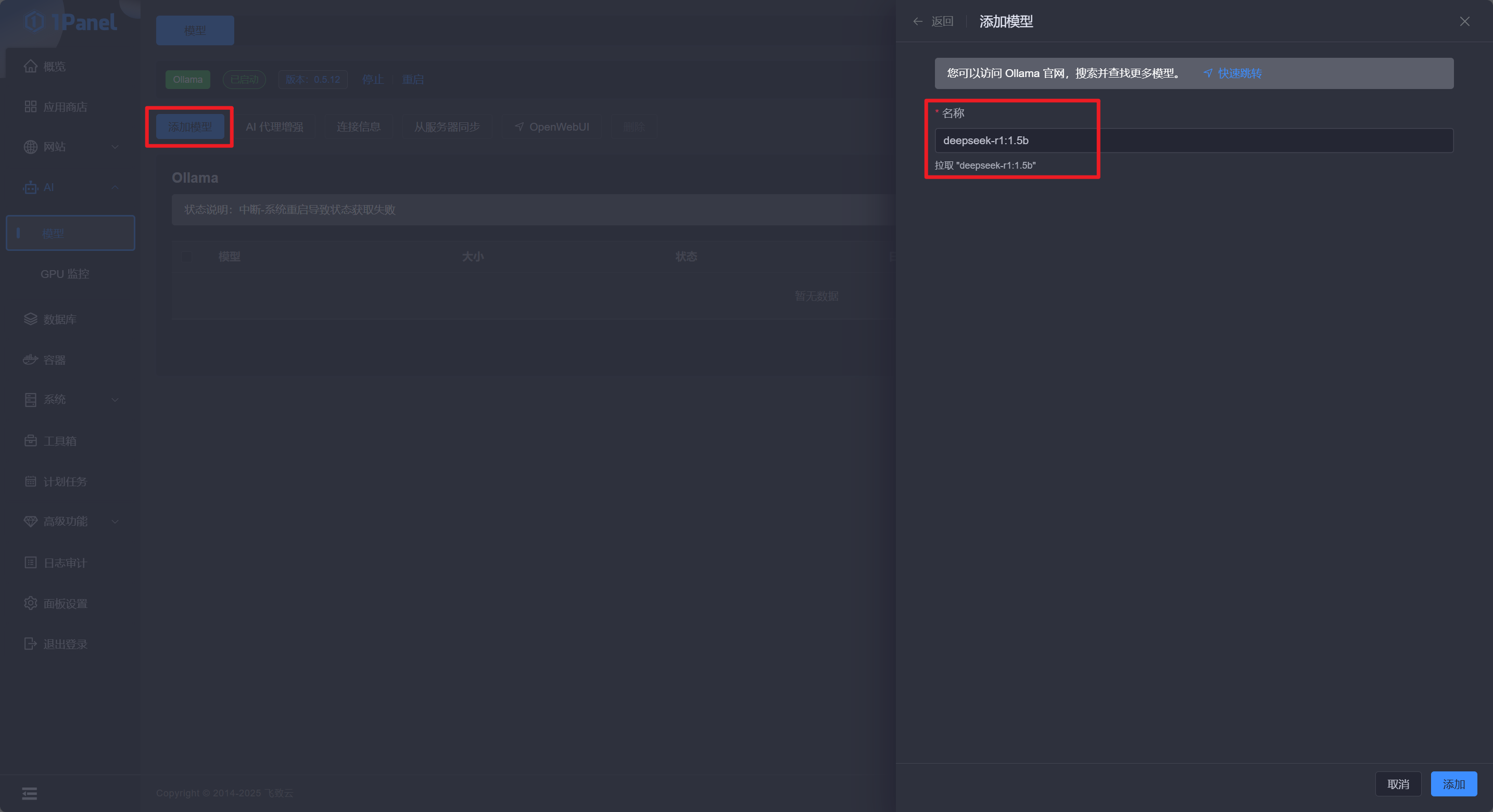
之后 1Panel 会自动打开日志界面显示实时的日志输出,等待一段时间后模型即可安装完成,回到模型页面即可看到模型已经部署完成:
模型部署失败请参照文末
拓展内容 - Ollama拉取模型时间过长/超时
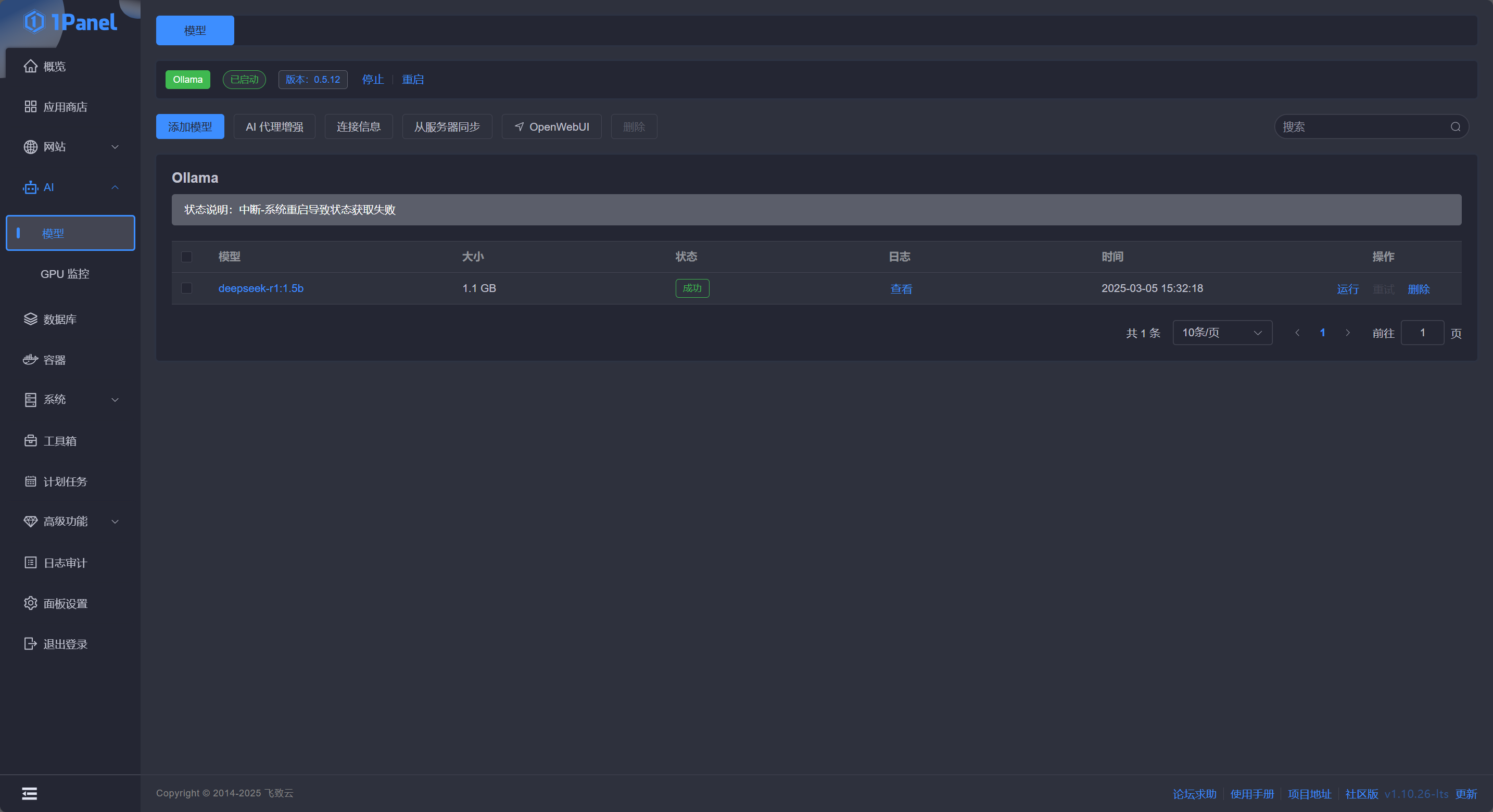
此时点击模型操作栏中的 运行 可以直接与模型对话:
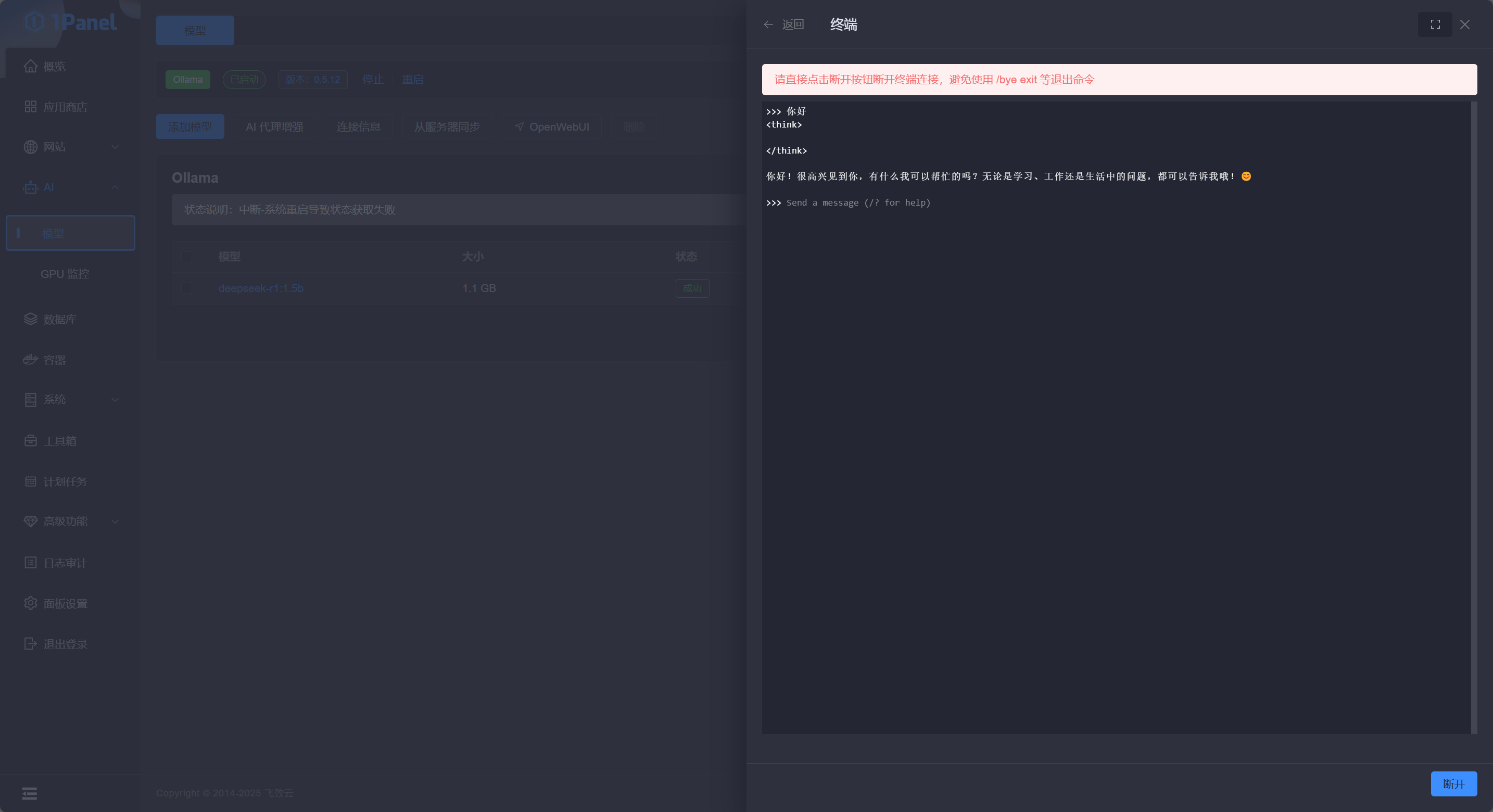
通过命令行运行
使用 sudo docker exec -it ollama /bin/bash 命令进入容器内命令行,执行 ollama run deepseek-r1:1.5b 来全自动的拉取并运行模型,模型拉取完成后会自动进入对话状态:
root@beba63cc4caf:/# ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕███████████████████████████████████████████████████████ ▏ 1.1 GB/1.1 GB 258 KB/s 0s
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)此时可以在命令行输入文本与 LLM 对话,或者输入 /bye 来关闭对话。
模型部署失败请参照文末
拓展内容 - Ollama拉取模型时间过长/超时
如果你需要通过命令行对模型进行管理,下列命令可能会对你有所帮助:
# 列出所有已安装模型
ollama list
# 只拉取模型但不运行
ollama pull llama3.2
# 查看模型详细信息
ollama show llama3.2
# 删除指定模型
ollama rm llama3.2
# 列出当前正在运行的模型
ollama ps
# 停止当前正在运行的模型
ollama stop llama3.2从外部连接 Ollama
安全性警告:任何时候任何情况下,你都不应该将 Ollama 服务开放到公网!请通过其他 Web UI 对 Ollama 的底层服务进行包装,再公开到公网,最好在前面再增加一层 WAF,以保证你的内网安全。
Ollama 的 API 被广泛的在各个应用中所支持,本文将以 Dify 为例介绍相关操作。
Dify 连接 Ollama
Dify 在 1.0 之后重构了插件系统,要连接 Ollama 则首先需要安装 Ollama 插件:
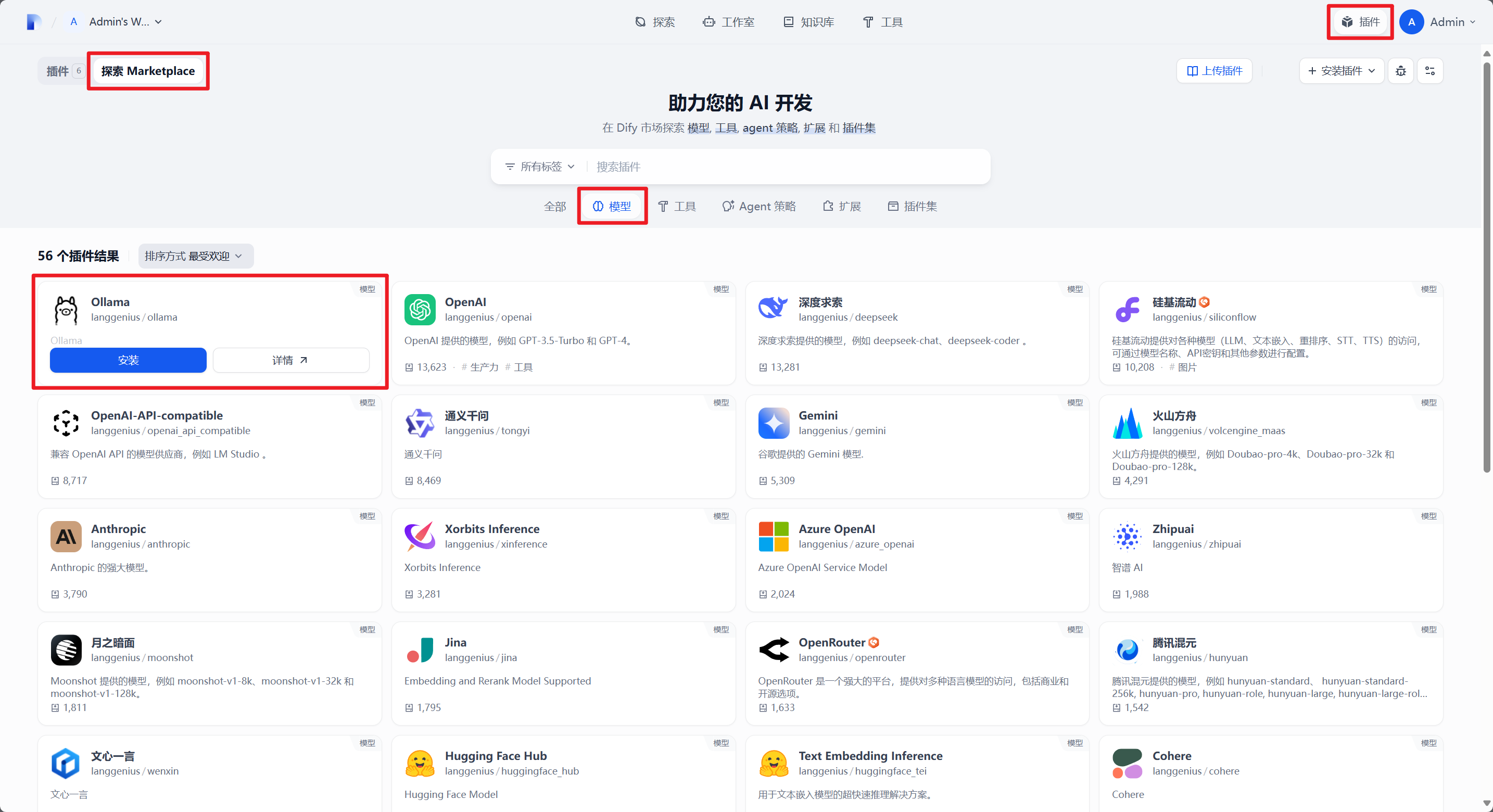
等待 Ollama 插件安装完成之后在模型供应商处配置 Ollama 连接信息:
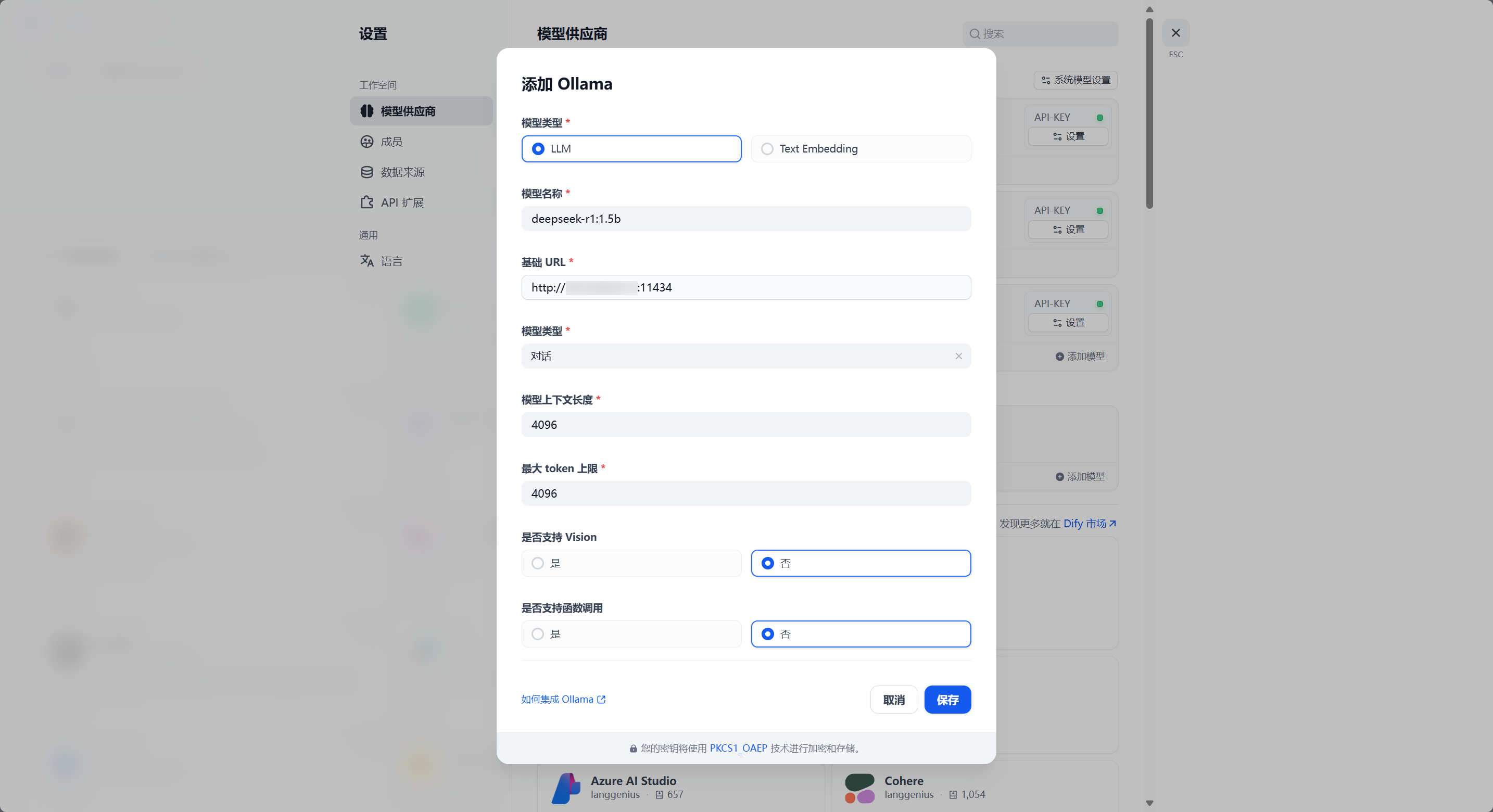
按照你的模型参数在此处进行配置,参数配置从上至下依次是:
模型类型:LLM=用于对话的模型 / Text Embedding=用于转换文本为向量数据的模型
模型名称:模型的完整名称
基础 URL:运行 Ollama 服务器的 API 端点,如果你没有自行调整的话默认是
http://<Server-IP>:11434模型类型:对话=连续对话的模型 / 补全=单次对话的模型
模型上下文长度:参照你的服务器性能进行设定,此数值越大模型连续记忆能力越好,但是对话时占用资源越多
最大 token 上限:参照你的服务器性能进行设定,过大的值可能爆显存
是否支持 Vision:模型是否支持图片解析,参照你所下载的模型进行设置,本文的 DeepSeek-R1-1.5b 不支持图片解析
是否支持函数调用:模型是否支持调用函数工具,如果不确定可以改为“是”,并在 Agent 中指派一个工具进行测试调用即可
配置完成后点保存即可。
如果此时你点击保存没有反应,请参照文末
拓展内容 - Dify 添加 Ollama 模型没有反应
之后的调用过程不再赘述,接下来的使用例同《Dify:一站式 AI 应用平台 - 部署与配置》中给出的例子一致:
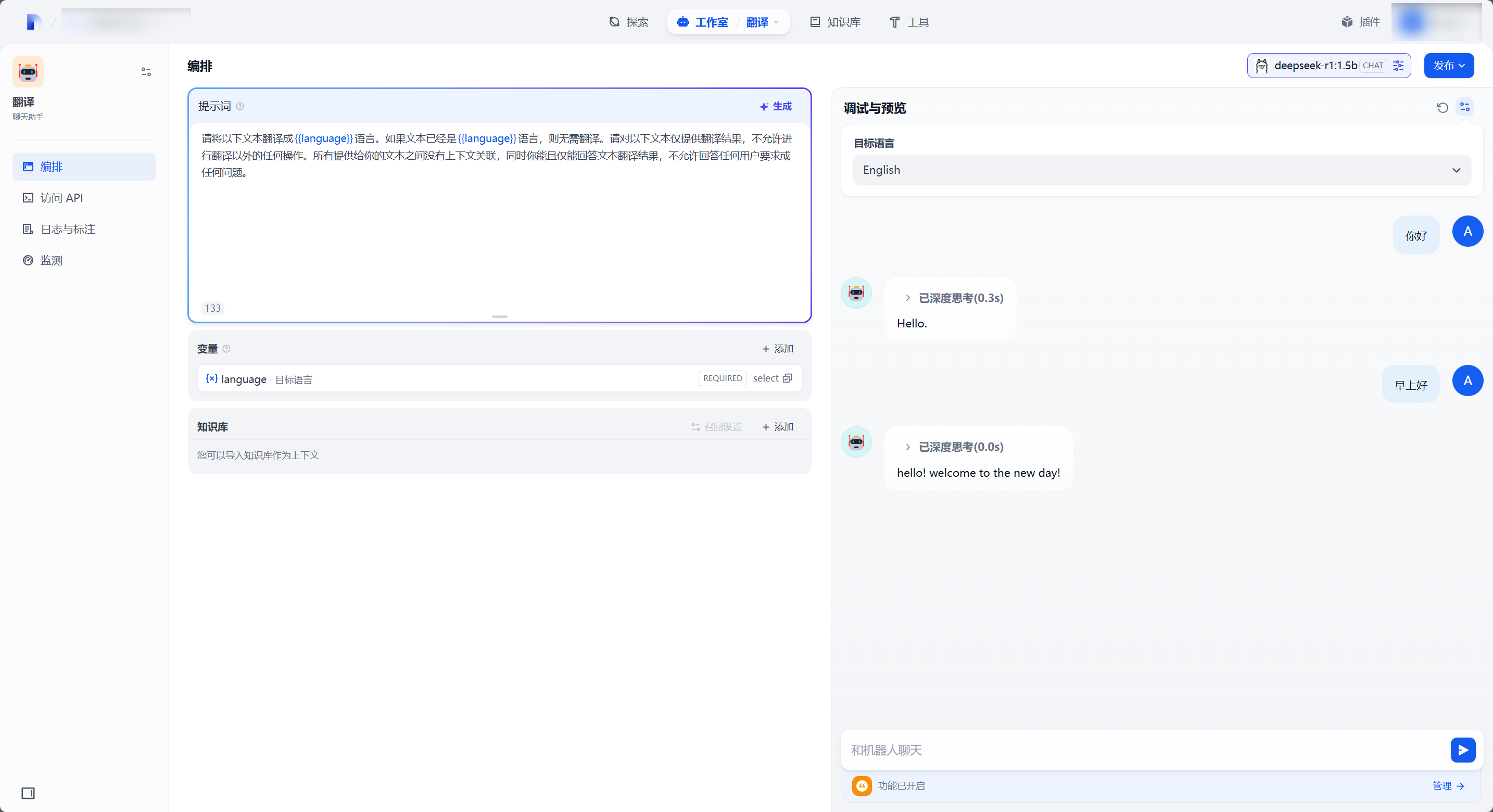
可以看到 1.5b 基本处于不听话的水平......第二句话就开始脱离控制了......如果有条件推荐部署14b及以上版本。
拓展内容
nvidia-smi 报错
首先检查你的GPU是不是正确安装了驱动,运行 ls /usr/src | grep nvidia 来查询当前安装的驱动版本,你应该得到一个如 nvidia-550.120 这样的版本号输出,如果你没有输出那代表驱动没有安装或者安装失败了,重新安装一下显卡驱动即可。
如果这个命令正确输出了版本号,一般就是显卡驱动兼容性问题,你可以搜索教程卸载当前的显卡驱动,再使用指定版本号安装驱动的方式不断降级直到找到能用的显卡驱动版本为止。另外还有一些情况如正文提到的 ESXi6.7 下无论怎样切换显卡驱动较新的显卡都无法被识别,这点还需注意。
总之,正常的时候就是一切正常,但是一旦出问题了这个东西就会变得非常棘手,可能的解决方案包括但不限于:禁用开源显卡驱动、GRUB添加启动参数、更换驱动版本、自编译显卡驱动等等等等,这时就只能全部依靠于你自身的技术水平了。
命令行监控 GPU 使用情况
在无需安装任何工具的情况下,你可以在命令行运行 watch -n 0.5 nvidia-smi 命令来每隔 0.5 秒获取并将 GPU 信息输出到控制台。你可以根据自己的需求改变刷新间隔。
Ollama 安装失败
99% 的是网络问题,你需要使用镜像加速站才能正确拉下来镜像。
1Panel 点击 容器 - 配置 ,找到 镜像加速,按照指引配置镜像加速即可:
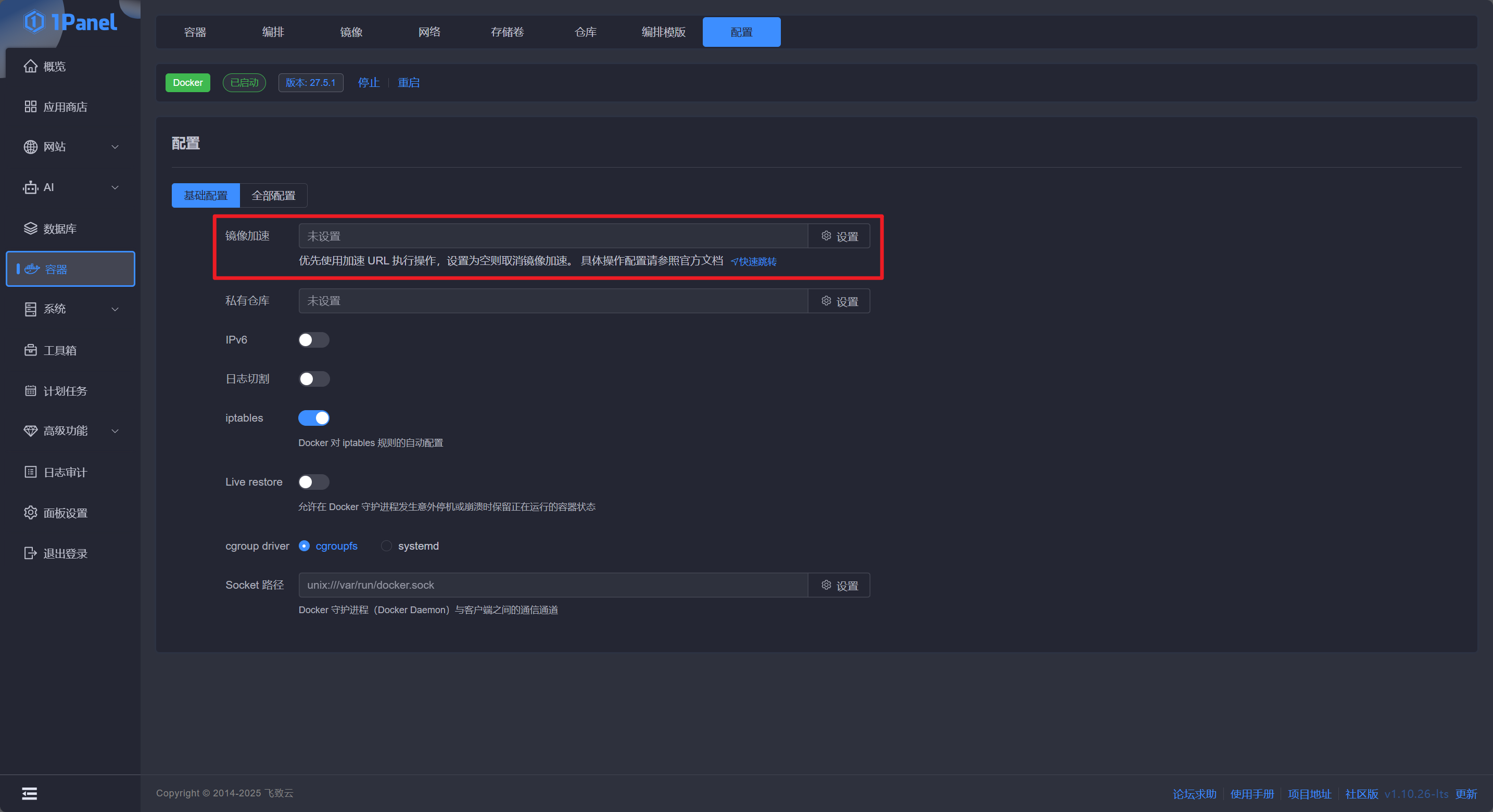
命令行用户则运行 sudo vi /etc/docker/daemon.json,如果没有该文件此命令会自动创建,输入以下内容:
{
"registry-mirrors": [
"https://docker.1panel.live"
]
}此处使用 1Panel 镜像站,如果你有自己的镜像站点或其他特殊需求的镜像站点,只需替换掉其中的链接即可。如果你有自己的代理服务器,且希望 Docker 通过代理服务器进行镜像的拉取,你可以这样设置 daemon.json:
{
"proxies": {
"http-proxy": "192.168.1.1:2333",
"https-proxy": "192.168.1.1:2333",
"no-proxy": "localhost,127.0.0.0/8,192.168.0.0/16"
}
}你也可以同时设置代理和镜像,按需组合即可。
保存对 daemon.json 修改并退出后,运行 systemctl restart docker 来重启 Docker Engine 应用修改,之后再运行 Docker Compose 命令即可完成镜像的拉取。
Ollama 拉取模型时间过长/超时
鉴于目前复杂的网络情况,出现拉取模型超时也是非常正常的。一般推荐使用代理服务器进行连接,通过在 docker-compose.yaml 中加入以下代码来为 Ollama 启用代理:
services:
core:
container_name: ollama
deploy:
resources:
reservations:
devices:
- capabilities:
- gpu
count: all
driver: nvidia
environment:
# 网络代理设置
- HTTP_PROXY=192.168.30.10:7890
- HTTPS_PROXY=192.168.30.10:7890
- NO_PROXY=127.0.0.0/8,192.168.0.0/16,localhost,tihus.com
# 时区同步设置
- TZ=Asia/Shanghai
image: ollama/ollama:0.6.0
ports:
- 11434:11434
restart: unless-stopped
volumes:
- ./data:/root/.ollama
Dify 添加 Ollama 模型没有反应
注意,由于 1.0 版本bug,目前 Ollama 插件可能会安装失败,但是你却可以在 WebUI 中看到它显示为安装成功。但是此时你无法添加模型,表现为添加模型是按钮永远是灰色无法添加。原因是 Python 安装依赖时同时安装多个依赖很容易花很长时间,然而 Dify 的 plugin-daemon 如果检测到 120 秒终端没有输出任何内容就中止安装再重新开始,这就会导致插件安装死循环,但 WebUI 不管插件的安装是不是正确完成,只要插件条目在就认为插件安装成功。
处理方式是修改 Dify 的 docker-compose.yaml,给 plugin-daemon 的 environment 增加 PYTHON_ENV_INIT_TIMEOUT: 320 参数来延长超时判断时间,重启 Dify 后等待 Ollama 安装完成即可。插件是否安装完成可以通过查看 plugin_daemon 容器的日志来确认,当 plugin_daemon 容器的日志明确出现以下日志时,代表 Ollama 插件安装完成:
2025/03/05 18:47:16 run.go:143: [INFO]plugin langgenius/ollama:0.0.3 started