如何使用 Grafana 监控系统性能指标 - Part 1
服务器太多了?想要知道某个服务是不是分配的资源不够了?每天都在担心是不是自己的 AIO 是不是 All in BOOM 了?
别担心,本篇教程将为你介绍一种更加复杂但是监控指标全面、可自定义程度极高的性能指标监控系统:Prometheus,根据你的配置它可以实现监控系统的各方面综合数据如CPU、内存、硬盘、网络等,也可以细化成监控单个容器的性能和资源占用,如果你想甚至可以按进程分析并监控你的服务器性能,那么话不多说,开始部署!
在开始之前
在我写完 Part 2 之后,我决定回来加上这个章节,来劝退一些想要尝试这套系统的小白:
你必须拥有基本英语阅读能力,因为 Grafana 系统汉化程度很低,关键操作全部都是英文,文档也是全英文。
你有对于可视化系统的使用需求,或者确实对自己的系统需要非常细致的监控需求,否则你付出的学习时间和你的收获将完全不对等。
你对于容器化有了解,能够自行部署 Docker Engine / Podman 且会编写和部署编排,能够排除基本的容器错误。
如果你不满足以上任意一点,那么建议立刻关闭此教程,因为它不值得你付出时间去学习。
简单介绍 Prometheus
诶!有人要问了,为啥标题写的是 Grafana 但是你介绍的是 Prometheus,这是因为这套监控系统是由三个部分构成:
性能指标收集器(node_exporter / cAdvisor / ...),用于收集目标服务器的性能指标
Prometheus 抓取所有收集器收集的性能指标并以时间线性存储下来以供数据可视化系统调用
Grafana 调用 Prometheus 的数据并将其绘制为最终的可视化数据大屏
所以严格来说 "性能指标收集器" + Prometheus 才是真正的性能指标监控部分,只不过到这一步所有的性能指标还都只是存储在 Prometheus 里的一堆数据而已。Grafana 实际上是将 Prometheus 的数据进行处理并绘制成可视化数据大屏,即最后一步的数据可视化并不一定要使用 Grafana,你也可以使用任意数据可视化系统,只要它能够支持读取 Prometheus 的数据即可。本篇教程选择 Prometheus + Grafana 的组合是因为这两个产品本就是一家出的,兼容性极好,同时全套系统都有社区版完全免费,以及 Grafana 有完善的社区支持,能找到的教程也相对会多些。
另外,单论监控来说,如果你不需要我上面说的那么细致的数据,只是想知道某个服务器是不是宕机了或者某个容器是不是宕机了,那么有很多简单的实现可以使用,比如 Uptime Kuma,它的部署和使用都非常简单,很适合新手使用。
本篇教程为 Part 1,主要介绍全套系统的部署和初步配置,关于 Grafana 仪表板的配置与编写请转下一篇 Part 2
部署性能指标收集器
在文章的开头有说,Prometheus 是一种更加复杂但是监控指标全面、可自定义程度极高的性能指标监控系统,这点在此时就有所体现,Prometheus 可以使用相当多的性能指标收集器,但本文只介绍几种我验证过的指标收集器,按照你的需求在其中选择性部署即可。
node_exporter 和 windows_exporter:设备硬件性能指标收集,比如CPU、内存、硬盘、网络等硬件方面的详细信息。
cAdvisor(Container Advisor):Google 出品,原生支持监控容器性能指标,支持 Docker / Podman 实现。除此以外,cAdvisor 还支持接收来自其他渠道的指标数据并将其转换为 cAdvisor 的数据格式合并输出,比如 TrueNAS 或 nginx 这种原生格式 Prometheus 无法读取的软件可以使用这种方式让 cAdvisor 将对应的数据转换为 Prometheus 可以读取的格式。但 cAdvisor 缺少硬件性能指标,建议只有当你需要 cAdvisor 监控容器或软件性能指标时再部署它。
Docker metrics:Docker 官方的性能指标收集器,是 Docker Engine 原生的功能之一,监控的指标较少且不全面,好处是作为 Docker Engine 的原生功能基本对性能没任何影响,不是很推荐使用,除非性能吃紧。
根据上面的描述你应该已经了解到每台设备 / OS 上可以部署多个收集器以实现对不同硬件 / 软件的指标监控,根据需要进行选择即可。推荐每台设备至少应该部署 node_exporter 用于导出基础硬件信息,在其上如果还需要其他功能再部署 cAdvisor 这种高级收集器。
node_exporter
node_exporter 同时支持 Linux 本地部署以及容器化部署。如果你的服务器有安装容器化实现则优先推荐使用容器化部署,方便快捷。
容器化部署
容器化部署所使用的 docker-compose.yaml 内容如下:
services:
core:
image: quay.io/prometheus/node-exporter:latest
command:
- "--path.rootfs=/host"
network_mode: host
pid: host
restart: unless-stopped
volumes:
- "/:/host:ro,rslave"不需要更改任何配置,node_exporter 会以只读方式挂载并读取系统数据将其保存在内存中以供 Prometheus 读取,不会对系统本身有任何影响。
本地化部署
如果你的系统里没有安装 Docker 或任何其他的容器化实现,则可以使用本地部署的方式,首先去 GitHub Release 下载你的 Linux 架构的安装包。比如 Ubuntu Server 24 则对应下载名为 node_exporter-[version].linux-amd64.tar.gz 的文件,并将其上传至你的用户文件夹,执行以下命令(注意文件名替换):
sudo tar -xvzf node_exporter-[version].linux-amd64.tar.gz
sudo mkdir /opt/node_exporter
sudo cp ./node_exporter-[version].linux-amd64/node_exporter /opt/node_exporter/
sudo chmod +x /opt/node_exporter/node_exporter执行完上述命令后,你应该能够在 /opt/node_exporter 路径下看到一个名为 node_exporter 的可执行文件。
然后使用 systemd 为 node_exporter 创建一个服务,以便于管理 node_exporter 和设置开机自启。
运行命令:sudo vi /etc/systemd/system/node_exporter.service,按下 i 键以进入编辑模式,写入以下内容:
[Unit]
Description = node_exporter
After = network.target syslog.target
Wants = network.target
[Service]
Type = simple
ExecStart = /opt/node_exporter/node_exporter
[Install]
WantedBy = multi-user.target写入完成后按下 esc ,输入 :wq 按下回车键保存并退出。使用 sudo systemctl enable node_exporter 来设置开机自启,然后使用 sudo systemctl start node_exporter 来启动 node_exporter,所有管理命令如下:
# 设置 node_exporter 开机自启
sudo systemctl enable node_exporter
# 关闭 node_exporter 开机自启
sudo systemctl disable node_exporter
# 启动 node_exporter
sudo systemctl start node_exporter
# 停止 node_exporter
sudo systemctl stop node_exporter
# 重启 node_exporter
sudo systemctl restart node_exporter
# 查看 node_exporter 状态
sudo systemctl status node_exporter如果一切安装无误的话,访问 http://<Machine-IP>:9100/metrics 即可看到设备硬件信息。
cAdvisor
cAdvisor 支持本地化和容器化部署,但其本地化部署与 node_exporter 并无太大区别,故此处不再介绍其本地化部署方式,本地化部署所需文件请参考 Github Release。关于 cAdvisor 如何监控其他软件如 nginx 可以查看官方文档,容器化部署所需的 docker-compose.yaml 配置如下:
services:
core:
devices:
- "/dev/kmsg:/dev/kmsg:r"
image: gcr.io/cadvisor/cadvisor:latest
ports:
- 8080:8080
privileged: true
restart: unless-stopped
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
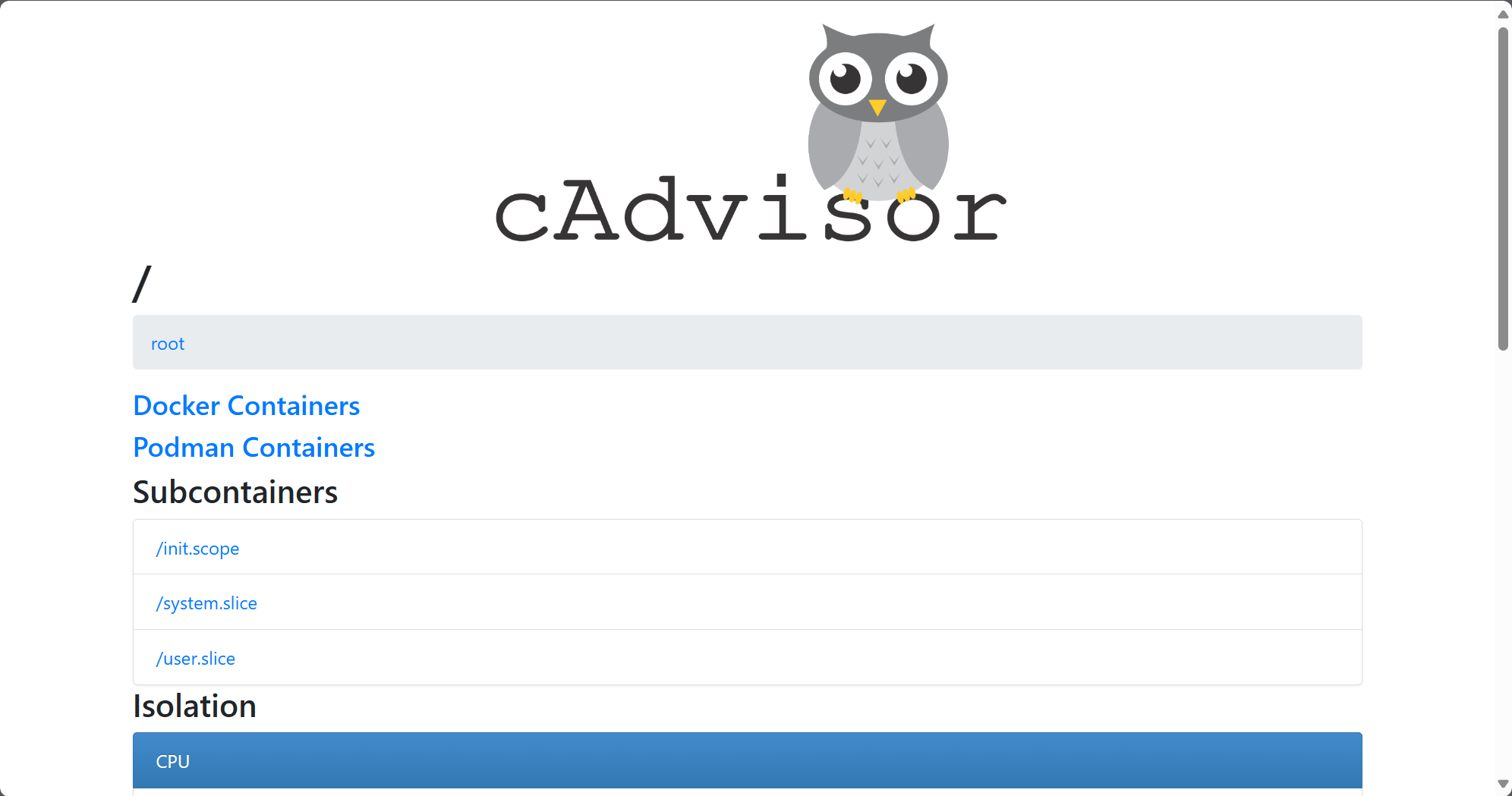
与 node_exporter 同样,cAdvisor 的配置也无需更改,它只会拥有对系统的只读权限,不会对系统造成任何影响。在部署完成之后,访问 http://<Machine-IP>:8080 可以打开 cAdvisor 的性能监控页面:
Docker Metrics
顾名思义,这个收集器是 Docker Engine 自带的一项功能,仅用于监控 Docker 自身的数据,官方文档链接点击这里。Docker Metrics 的使用前提是你必须安装 Docker Engine 作为容器化实现。
在 Linux 终端中,执行 sudo vi /etc/docker/daemon.json 来修改 Docker Engine 配置,在其中添加以下内容:
{
"metrics-addr": "0.0.0.0:9323"
}写入完成后按下 esc ,输入 :wq 按下回车键保存并退出,执行 sudo systemctl restart docker 来使配置生效即可。如果一切配置无误的话,访问 http://<Machine-IP>:9323/metrics 即可看到设备硬件信息。
Prometheus 的部署与配置
Prometheus 支持本地化部署与容器化部署,有关于本地化部署可以参考官方文档,基本步骤与 node_exporter 的本地化部署一致即 下载安装包-解压缩到合适路径下-创建 systemd 服务并设置开机自启 ,故此处仅介绍容器化部署及配置上的内容。容器化部署所需的 docker-compose.yaml 内容如下:
services:
core:
# 历史数据保留时间,默认为15d(天),如果你不需要设置数据保存时间可以删除 command 块
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.retention.time=15d
environment:
- TZ=Asia/Shanghai
image: prom/prometheus:latest
ports:
- 9090:9090
restart: unless-stopped
uid: 0:0 # 注意:如果你手动创建以下 ./data/data 和 ./data/cfg 文件夹并赋予普通用户权限,则此处可以不设置为 root 身份运行
volumes:
- ./data/data:/prometheus
- ./data/cfg:/etc/prometheus注意,此处的 volumes 字段中,./data/data 是 Prometheus 的数据存储目录,./data/cfg 是 Prometheus 的配置文件目录,你可以按照自己的需求更改这些文件的存储路径。
此时这个编排启动就会报错,因为 Prometheus 需要知道去哪里以及怎样抓取性能指标数据。在 ./data/cfg 目录(如果你更改了那就按自己的路径来)下创建一个名为 prometheus.yml 的文件(注意大小写以及文件拓展名),按照下列方式对 Prometheus 进行配置:
global:
# 抓取性能指标的频率,默认为1m,格式为 [0-9]+[smhdwy](秒分时日周年),可以为复合值如 1m30s 表示1分30秒
scrape_interval: 1m
# 性能指标收集器配置,每一个 job 代表一个性能指标收集器,如果一台服务器配置了多个收集器则需要配置多个 job
scrape_configs:
# 收集器配置示例说明:
# job_name 是收集器的唯一标识,在后续 Grafana 可视化时会用到,请为每一个 job 设置一个唯一且有意义的名称
- job_name: 'prometheus'
# 此项设置收集器抓取性能指标的路径,一般无需更改
metrics_path: /metrics
# 此项设置 Prometheus 与收集器之间的通讯协议,如果你使用了 tls 则此处可以设置为 https
scheme: http
# 此项单独设置某一个 job 的抓取频率,默认使用 global 中的 scrape_interval
scrape_interval: 5s
# static_configs 一般只需设置 targets 即可,不同的收集器此处配置的连接不同
static_configs:
- targets: ['localhost:9090']
# 以下为特定收集器的示例配置:
# 使用 Node Exporter:
- job_name: 'node_exporter'
static_configs:
- targets: ['<Node-Exporter-IP>:9100']
# 使用 cAdvisor:
- job_name: 'cadvisor'
static_configs:
- targets: ['<cAdvisor-IP>:8080']
# 使用 Docker Matrices:
- job_name: 'docker'
static_configs:
- targets: ['<Docker-IP>:9323']完成 prometheus.yml 的配置以后,重新启动编排,看到如下日志输出即代表 Prometheus 的配置无异常:
time=2025-02-14T09:03:45.450Z level=INFO source=main.go:1209 msg="Server is ready to receive web requests."此时访问 http://<Prometheus-IP>:9090/targets 可以看到 Prometheus 中所监测的收集器状态,末尾的绿色 up 代表对应的收集器工作正常。

至此 Prometheus 的部署和初始化设置完成。
Grafana 的部署与配置
Grafana 支持本地化部署与容器化部署,本地化部署请参考官方文档,本文只介绍容器化部署方式,docker-compose.yaml 内容如下:
networks:
1panel-network:
external: true
services:
core:
dns:
- 192.168.30.1
environment:
- TZ=Asia/Shanghai
- GF_PATHS_CONFIG=/var/lib/grafana/grafana.ini
image: grafana/grafana-enterprise:11.5.1
networks:
- 1panel-network
ports:
- 3000:3000
restart: unless-stopped
uid: 0:0 # 注意:如果你手动创建以下 ./data 文件夹并赋予普通用户权限,则此处可以不设置为 root 身份运行
volumes:
- ./data:/var/lib/grafanaGrafana 同样有自己的配置文件,在启动此编排前,你需要在 ./data 目录(如果你更改了那就按自己的路径来)中创建 grafana.ini 文件(注意大小写与拓展名),创建完成后跟随如下示例按需进行配置:
[server]
; 设置根 URL,如果你需要设置 SSO 登录或需要反向代理将 Grafana 挂载到域名的子 URL 时需设置此项。
; 比如你的域名是 yourdomain.com,你想把 yourdomain.com/grafana 设置为访问 Grafana,那么此处就应该设置为 https://yourdomain.com/grafana
root_url = https://grafana.yourdomain.com
; 如果需要反向代理将 Grafana 挂载到域名的子 URL 时,此项必须设置为 true
serve_from_sub_path = false
; 启用 Gzip 压缩,可以节省带宽,如果运行 Grafana 的服务器性能不是特别吃紧的话建议设置为 true
enable_gzip = false
; Grafana 默认使用 sqlite3 作为数据库存储,如果你没有像我一样有专门的 PostgreSQL 数据库服务器的话可以不设置 database 块
[database]
; 要使用的数据库类型,可以是 mysql, postgres or sqlite3
type = postgres
; 数据库主机链接地址
host = 127.0.0.1:5432
; 数据库名
name = grafana
; 数据库用户名
user = username
; 数据库用户密码
password = password
[analytics]
; 使用数据反馈,建议关闭
reporting_enabled = true
[security]
; 用于加密敏感数据(如用户凭据)的密钥
secret_key = 请生成一串随机的英文大小写+数字的字符串使用
; 禁用 Gravatar 头像集成,没什么用建议设置为 true 禁用集成
disable_gravatar = false
; 如果你反代启用了 https 则建议此项设为 true 以增强安全性
cookie_secure = false
; 禁止网页嵌套,如果你有将 Grafana 页面嵌入到其他站点的需求可以将此项设置为 true
allow_embedding = false
[dashboards]
; 当你修改仪表板时历史版本的保存数量,建议缩小到5
versions_to_keep = 20
[users]
; 默认用户界面语言,设置为 zh-Hans 来默认使用简体中文
default_language = en-US
[auth]
; 用户登录后的默认非活动会话有效期,默认 7d 太长了,建议缩短到 30m
login_maximum_inactive_lifetime_duration = 7d
; 用户登录后的会话有效期,默认 30d
login_maximum_lifetime_duration = 30d
[smtp]
; 启用 SMTP 邮件服务,如果你需要用邮件接收告警通知则需要配置
enabled = false
; SMTP 服务器地址,隐式 TLS 使用 465 端口
host = localhost:25
; SMTP 服务用户名
user = username
; SMTP 服务密码
password = password
; SMTP 发送人名称
from_name = Grafana
[emails]
; 当新用户注册时自动发送一封欢迎邮件
welcome_email_on_sign_up = false
[metrics]
; Grafana 内部指标监控,如果你需要监控 Grafana 自身的性能数据可以保留,否则设为 false 以禁用
enabled = true如果你面对这么多设置项感到头晕,那么以下有一份已经配置好的配置项,将注释中的几项设置按需更改后直接CV即可使用:
[server]
; 启用 Gzip 压缩
enable_gzip = false
[analytics]
; 禁用使用数据反馈
reporting_enabled = false
[security]
; 敏感数据加密密钥
secret_key = 请生成一串随机的英文大小写+数字的字符串使用
; 禁用 Gravatar 头像集成
disable_gravatar = true
[dashboards]
; 仪表板历史版本的保存数量
versions_to_keep = 5
[users]
; 默认用户界面语言使用简体中文
default_language = zh-Hans
[auth]
; 用户登录后的默认非活动会话有效期缩短到 30m
login_maximum_inactive_lifetime_duration = 30m
[metrics]
; 禁用 Grafana 内部指标监控
enabled = false现在启动 Grafana 编排,在 http://<Grafana-IP>:3000 即可打开登陆界面,默认用户的用户名和密码均为 admin。

警告:如果你设置了 root_url,则在此时必须设置好反代及域名映射才能正确访问 Grafana,使用 IP:端口 访问会出现无法登录系统的问题。
至此 Grafana 的部署和初始化完成。
在 Grafana 中配置 Prometheus 数据源
诶!现在所有的组件都齐了,但是你会发现:woc这都啥啊,Grafana 的界面怎么那么复杂,什么是仪表板,我该怎么从 Prometheus 里搞出数据?别急!这份无止境的折腾之旅,马上就要结束了,你能把整套系统搭建起来不报错的整合到一起已经超越了 99% 的 Home Server 爱好者了。
首先让 Grafana 能够从 Prometheus 中读取数据,依次点击侧边栏 连接-添加新连接,在打开的页面上方搜索 Prometheus,点击它。

在弹出的新页面里点击右上角的 Add new data source

在新的页面中填写你的 Prometheus 链接地址,如果你跟随教程一步步来的话那么链接地址是 http://<Prometheus-IP>:9090/targets
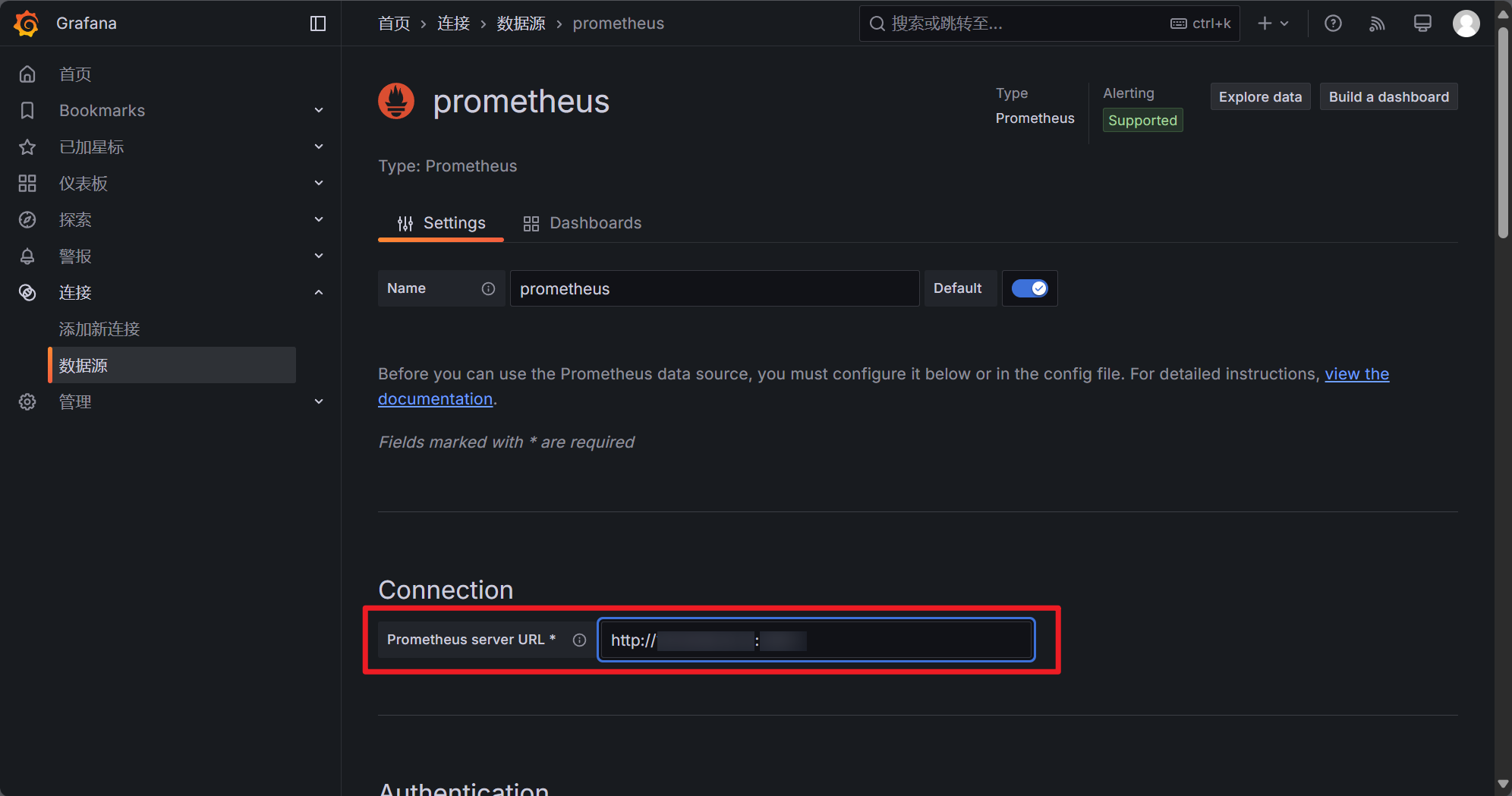
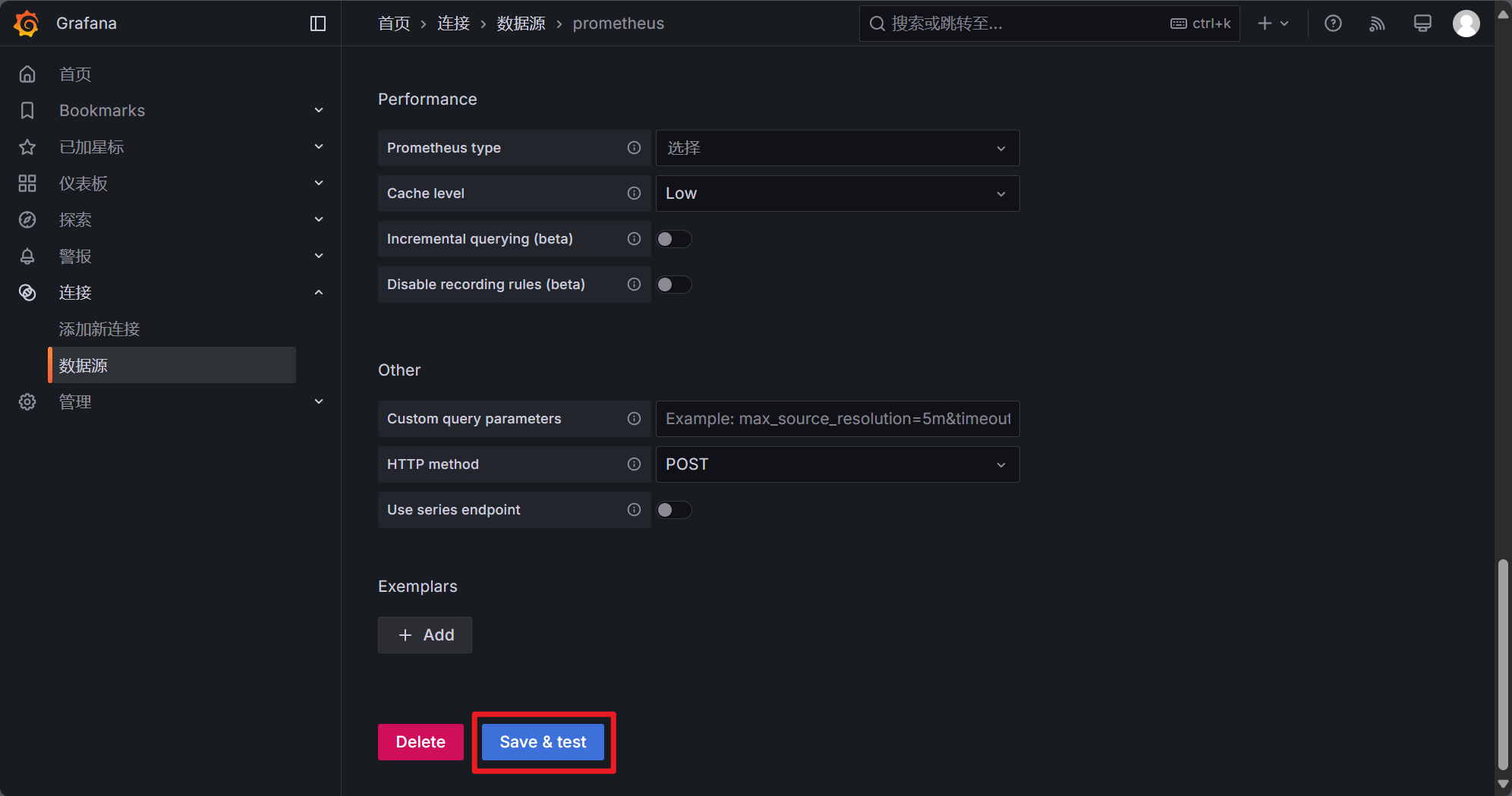
之后滚动到页面底部,点击 Save & test
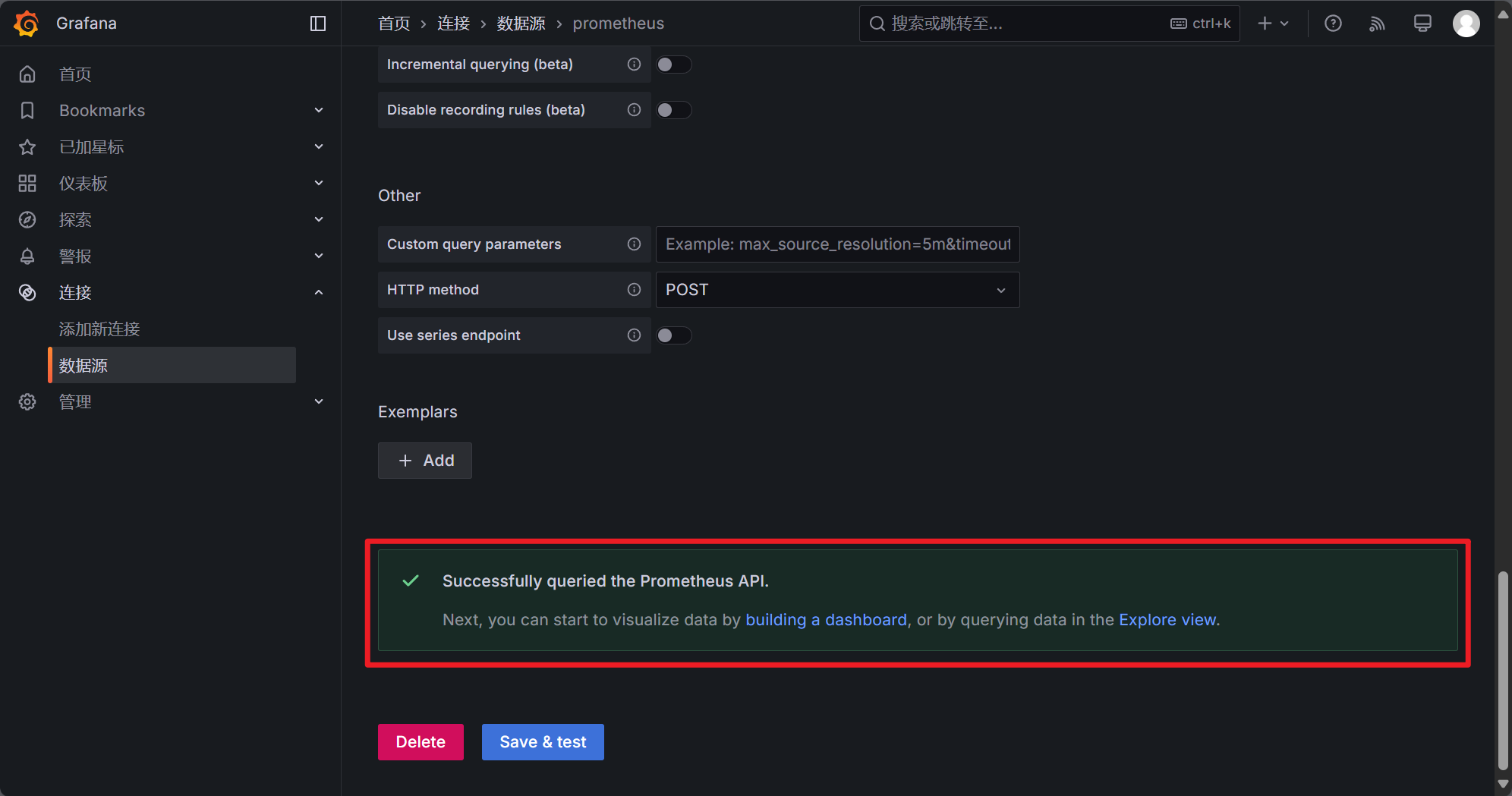
如果你连接地址没输错的话出现如下提示即代表 Prometheus 设置完成了
点击侧边栏 数据源 即可看到设置完成的 Prometheus 数据库状态

现在你的 Grafana 可以从 Prometheus 里读取性能指标数据了。
创建第一个仪表板
首先恭喜你,你终于坚持到了这里,至此你已经完成了整套系统约 80% 的部分,剩下 20% 是学习 Grafana 的可视化语法,将 Prometheus 的数据展示出来。不过这 20% 是相当复杂的内容,所以只能在 Part 2 中再行讲解,现在,先让我们搞一个简单的系统在线状态指示吧。
首先点击侧边 仪表板,然后点击中间的 Create dashboard

在新的页面中点击 导入仪表板

弹窗选择 Discard
此处用于演示的仪表板代码如下:
{
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": {
"type": "grafana",
"uid": "-- Grafana --"
},
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"id": 2,
"links": [],
"panels": [
{
"datasource": {
"type": "prometheus",
"uid": "${ds}"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "thresholds"
},
"mappings": [
{
"options": {
"0": {
"color": "red",
"index": 2,
"text": "离线"
},
"100": {
"color": "green",
"index": 0,
"text": "在线"
}
},
"type": "value"
},
{
"options": {
"from": 0,
"result": {
"color": "orange",
"index": 1,
"text": "部分离线"
},
"to": 99
},
"type": "range"
},
{
"options": {
"match": "null+nan",
"result": {
"color": "red",
"index": 3,
"text": "错误"
}
},
"type": "special"
}
],
"thresholds": {
"mode": "percentage",
"steps": [
{
"color": "red",
"value": null
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 0
},
"id": 1,
"options": {
"colorMode": "value",
"graphMode": "none",
"justifyMode": "auto",
"orientation": "auto",
"percentChangeColorMode": "standard",
"reduceOptions": {
"calcs": [
"lastNotNull"
],
"fields": "",
"values": false
},
"showPercentChange": false,
"textMode": "auto",
"wideLayout": true
},
"pluginVersion": "11.5.1",
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "${ds}"
},
"editorMode": "code",
"exemplar": false,
"expr": "(sum(up) / count(up)) * 100",
"instant": false,
"legendFormat": "在线节点",
"range": true,
"refId": "A"
}
],
"title": "系统状态",
"transparent": true,
"type": "stat"
}
],
"preload": false,
"refresh": "",
"schemaVersion": 40,
"tags": [],
"templating": {
"list": [
{
"allowCustomValue": false,
"label": "Datasource",
"name": "ds",
"options": [],
"query": "prometheus",
"refresh": 1,
"regex": "",
"type": "datasource"
}
]
},
"time": {
"from": "now-6h",
"to": "now"
},
"timepicker": {},
"timezone": "browser",
"title": "Testbench",
"version": 3,
"weekStart": ""
}
在新的页面中点击 Import

现在你就能看到自己的监控系统状态了,在此示例中,如果你配置了多于1个收集器且此时有收集器离线则仪表板会显示“部分离线”,如果一切正常则会显示“在线”

至此,Prometheus + Grafana 的完整系统部署与配置完成,你可以在 Grafana 中的“探索”页中玩一玩这些性能监控数据,关于怎样编写自己的仪表板,怎样将仪表板公开出去以供别人查看,这些内容将会在 Part 2 中进行讲解,Part 1 的内容到这里就结束了。
拓展内容
Grafana 的 SSO 配置
如果你的 SSO 不使用 OIDC 或你需要接入商用 SSO 比如 Github、Azure 等你需要参考官方文档来对你的 Grafana 进行配置。本章节仅介绍通过如何设置 Generic OAuth 的方式来接入你自己的 OIDC SSO 系统,在 grafana.ini 中按照下列指引添加配置:
[auth]
disable_login_form = true ; 注意:此项会禁用登陆框,请务必先把管理员权限转让给至少1名 SSO 用户后再将此项设置为 true
[auth.generic_oauth]
enabled = true
name = Generic-OAuth ; 登陆方式的显示名,会显示在 Grafana 登陆界面,按需更改
allow_sign_up = true ; 当 SSO 登陆的用户未在系统中注册时,自动使用 SSO 的用户信息在 Grafana 中创建用户,一般无需更改
client_id = client_id ; APP ID
client_secret = client_secret ; APP 密钥
scopes = openid email profile offline_access roles ; 字段授权,一般无需更改
email_attribute_path = email ; 用户邮箱字段
login_attribute_path = username ; 用户名字段
name_attribute_path = name ; 用户显示名字段
auth_url = https://xxx.com/auth ; SSO Auth 端点
token_url = https://xxx.com/token ; SSO Token 端点
api_url = https://xxx.com/userinfo ; SSO UserInfo 端点
; 用户权限判断,此处要按照自己 SSO 的设置进行调整,如果此配置错误可能会导致权限泄露给不应该拥有管理权的用户!
role_attribute_path = contains(group[*], 'admin') && 'Admin' || contains(group[*], 'editor') && 'Editor' || 'Viewer'如果一切正常现在你的登录页会变成如下样式:

点击登陆之后即可通过 SSO 自动登入系统。